
Didaktische Kernidee: Vermittlung von Epistemischem Programmieren als Mittel zum Erkenntnisgewinn im Kontext von Datenexplorationen
Der hier beschriebene Ansatz des Epistemischen Programmierens stellt eine erkenntniszentrierte Perspektive auf das Programmieren dar, die den Schüler*innen in diesem Unterrichtsmodul vermittelt werden soll. Auf diese Weise sollen Schüler*innen Programmieren als ein Mittel erfahren, das man im Alltag nutzen kann, um persönlich oder gesellschaftlich relevante Sachverhalte (datengetrieben) erkunden zu können. In dieser Hinsicht lernen die Schüler*innen, wie sie Datenexplorationsprojekte mittels Programmieren durchführen und auf diese Weise eigenen Erkenntnisinteressen nachgehen können. Dies bezieht sich einerseits auf die Sammlung und Auswertung von Zeitreihendaten (= Daten, die in einem bestimmten Messintervall wiederholt erhoben werden) entsprechend der eigenen Ziele, andererseits aber auch auf die Entwicklung von Computational Essays zur nachvollziehbaren und reproduzierbaren Dokumentation des Erkenntnis- und Programmierprozesses. Insbesondere lernen die Schüler*innen einzelne Schritte in der Datenanalyse kennen (wie Filtern, Erstellen von Visualisierungen oder Berechnen bestimmter statistischer Kenngrößen) und in diesem Kontext, wie sich systematisch Informationen aus Daten gewinnen lassen.
Die Praktik des (datengetriebenen) epistemischen Programmierens erfolgt in diesem Unterrichtsmodul anhand der Durchführung eines eigenen Projektes im Kontext umweltbezogener Fragestellungen. Dabei entwickeln die Schüler*innen eigene Erkenntnisinteressen, denen sie im Rahmen ihres Projektes nachgehen. In diesem Rahmen lernen sie den oben beschriebenen Prozess des Epistemischen Programmierens kennen und wie sie durch diese Interaktion mit dem digitalen Artefakt zu neuen Erkenntnissen gelangen können.
Im ersten Teil des Unterrichtsmoduls lernen die Schüler*innen Kriterien für gute statistische Fragestellungen kennen und dabei besonders auch, wie diese entwickelt werden können, indem sie eigene Fragestellungen unter der Verwendung eines Kriterienkatalogs entwickeln und gleichzeitig anderen Schüler*innengruppen Rückmeldung zu ihren Fragestellungen geben.
Im zweiten Teil lernen die Schüler*innen, wie sie basierend auf ihrer final entwickelten Fragestellung geeignete Daten sammeln oder selbst erheben können. Dabei können sie entweder kennenlernen, wie Arduinos/Senseboxen durch Programmierung und Anschluss entsprechender Sensoren zur Erhebung von Umweltdaten genutzt werden können oder aber verschiedene Plattformen für (Umwelt-)Daten kennenlernen und wie hier Daten systematisch ausgewählt und heruntergeladen werden können, um sie für die eigene Datenauswertung nutzbar zu machen. Die systematische Herangehensweise an die Datensuche wird dabei vermittelt, um den eigenen Erkenntnisinteressen nachgehen zu können. Alternativ kann dieser zweite Teil auch ausgelassen werden und es kann direkt über ein Jupyter Notebook (name.ipynb) auf bestimmte Daten zu beliebigen Orten und beliebigen Zeitpunkten seit 2001 zugegriffen werden. In diesem Fall können die Daten direkt über ein Jupyter Notebook geladen und auch in diesem analysiert werden.
Im dritten Teil führen die Schüler*innen die Datenanalyse im Kontext ihres epistemischen Programmierprojektes in einem Jupyter Notebook mit der Programmiersprache Python durch. Dabei lernen sie verschiedene Schritte und Aktionen kennen, um die gesammelten Daten einzulesen, aufzubereiten, zu filtern, zu visualisieren und anderweitig auszuwerten. Gleichzeitig lernen sie durch das Erstellen ihres Computational Essays kennen, ihren Programmier- und Erkenntnisprozess nachvollziehbar und reproduzierbar zu dokumentieren. Zur Umsetzung hinsichtlich ihres eigenen Projektes erwerben die Schüler*innen dabei grundlegende Fähigkeiten in der Python-Programmierung. Dies bezieht sich insbesondere auch auf Programmlesekompetenzen, die bei der Nutzung der Worked Examples benötigt werden, um den bereits bestehenden Code im Worked Example bzw. aus den dort verwendeten Bibliotheken nachvollziehen zu können und anschließend für das eigene Projekt nutzbar zu machen. Ebenfalls werden grundlegende Python-Konstrukte (insbesondere im Rahmen eines kurzen Python-Grundkurses) vermittelt, welche die Schüler*innen in ihrer Datenauswertung anwenden können.
Im vierten Teil tauschen sich die einzelnen Schüler*innengruppen hinsichtlich ihrer entwickelten Computational Essays aus, sodass sie sich in die jeweils anderen Computational Essays und die darin durchgeführte Datenexploration einarbeiten und diese nachvollziehen und bewerten. Auch hier werden insbesondere auch die Programmlesekompetenzen der Schüler*innen gefördert. Außerdem lernen sie durch den Austausch mit den anderen Gruppen weitere Beispiele für epistemische Programmierprojekte kennen.
Im fünften Teil reflektieren die Schüler*innen die Perspektive des Epistemischen Programmierens und die Rolle von Datenanalysen im Kontext der Exploration persönlicher Interessen. In dieser Phase soll dabei auch die Interaktion zwischen programmierender Person und digitalem Artefakt herausgearbeitet und diskutiert werden, wobei besonders die Rollen dieser beiden Akteur*innen analysiert werden sollen. Zudem entwickeln die Schüler*innen in dieser Phase weitere Ideen und Fragestellungen, die im Rahmen von datengetriebenen epistemischen Programmierprojekten adressiert werden können.
Target group
Informatikkurse sowie fächerübergreifende (GeoMINT) Kurse in Klasse 8 bis 10 (Gymnasium, Gesamtschule)
Inhaltsfelder nach dem Kernlehrplan WP Informatik NRW (24.05.2023)
- „Information und Daten“,
- „Algorithmen“,
- „Informatik, Mensch und Gesellschaft“,
- „Informatiksysteme“
Prior knowledge
Time scope
ca. 16 Unterrichtsstunden je 45 Minuten (ohne eigene Datenerhebung)
ca. 20 Unterrichtsstunden je 45 Minuten (mit eigener Datenerhebung)
Goals
Übergeordnete Ziele
- (Grobziel) Die Schüler*innen lernen datengetriebenes epistemisches Programmieren als Mittel zur Datenexploration im Kontext eines persönlich relevanten umweltbezogenen Sachverhalts kennen.
- (Feinziele) Die Schüler*innen führen im Kontext einer eigenen umweltbezogenen Forschungsfrage ein datengetriebenes epistemisches Programmierprojekt als Epistemic Agents durch, indem sie (eigene) Daten sammeln und auswerten sowie die Auswertungen interpretieren und damit Erkenntnisse hinsichtlich einer persönlich oder gesellschaftlich relevanten Fragestellung entwickeln.
Ziele der Teilabschnitte des Unterrichtsmoduls
- Teil 1: Erarbeitung initialer Fragestellungen/Forschungsinteressen
- Die Schüler*innen lernen die Exploration von Daten als Methode zur objektiven Beantwortung von persönlich oder gesellschaftlich relevanten Fragestellungen kennen.
- Die Schüler*innen kennen Kriterien guter und beantwortbarer statistischer Fragestellungen.
- Die Schüler*innen entwickeln statistische Fragestellungen für ein datengetriebenes epistemisches Programmierprojekt, indem sie die zuvor kennengelernten Kriterien befolgen.
- Die Schüler*innen bewerten von anderen Schüler*innengruppen entwickelte Forschungsfragen und geben kriteriengeleitetes Feedback und entwickeln Verbesserungsvorschläge.
- Die Schüler*innen identifizieren zu untersuchende Variablen, die in ihren entwi-ckelten Forschungsfragen enthalten sind.
- Teil 2: Daten sammeln
- a) Daten mithilfe eines Messinstrumentes selbst erheben
- Die Schüler*innen entwickeln einen Plan zur Erhebung von Daten, die ihnen eine Exploration in Bezug zu ihrer zuvor formulierten Forschungsfrage ermöglichen.
- Die Schüler*innen entwickeln ein Messinstrument zur Erhebung von Daten, indem sie eine Sensebox/einen Arduino entsprechend aus passenden Komponenten und Sensoren zusammenbauen.
- Die Schüler*innen entwerfen und implementieren ein Programm zur Datenerhe-bung mit der Sensebox/einem Arduino.
- b) Daten aus verschiedenen Quellen sammeln und zusammentragen
- Die Schüler*innen entwickeln einen Plan zur Sammlung von Daten, die ihnen eine Exploration in Bezug zu ihrer zuvor formulierten Forschungsfrage ermöglichen.
- Die Schüler*innen identifizieren geeignete Datenquellen und generieren/laden Datensätze im Hinblick auf ihre Forschungsfrage
- a) Daten mithilfe eines Messinstrumentes selbst erheben
- Teil 3: Datenexploration und verwobener Erkenntnis- und Programmierprozess
- Die Schüler*innen kennen wichtige Methoden zum Einlesen, Aufbereiten Filtern, Visualisieren und Auswerten von Zeitreihendaten sowie grundlegende Python-Befehle, um diese Methoden hinsichtlich ihres eigenen Projektes anzuwenden bzw. zu kombinieren.
- Die Schüler*innen nutzen das zur Verfügung gestellte Worked Example, indem sie Code daraus adaptieren und erweitern und die Sequenzierung – angepasst für ihr eigenes Projekt – übernehmen.
- Die Schüler*innen führen die wesentlichen Schritte „Daten einlesen“, „Daten aufbereiten“, „Daten filtern“, „Daten visualisieren und auswerten“ im Datenexplorationsprozess aus.
- Die Datenaufbereitung besteht dabei mindestens aus der Vergabe der richtigen Datentypen sowie aus dem Setzen des Index.
- Bei der Visualisierung und Auswertung der Daten können die Schüler*innen zwischen verschiedenen Methoden und Herangehensweisen wählen, die im Worked Example gezeigt werden. Dies sind insbesondere die Visualisierung als Scatter- oder Boxplots (mit mehreren Plots), die Berechnung wesentlicher statistischer Kennwerte (min/max/mean), die Gruppierung von Datensätzen sowie die Berechnung von Korrelationen.
- Die Schüler*innen kennen Eigenschaften und Nutzungsweisen eines Computational Essays.
- Die Schüler*innen kommunizieren ihren Erkenntnis- und Programmierprozess auf nachvollziehbare und reproduzierbare Weise, indem sie schrittweise ein Computational Essay entwickeln und darin Codezellen, Code-Output-Zellen und Textzellen kombinieren.
- Die Schüler*innen führen epistemische Programmierprozesse aus, indem sie spiralartig neue Handlungsschritte aus ihren Erkenntnissen ableiten, diese in Form von Programmcode implementieren und vom Computer ausführen lassen.
- Teil 4: Vorstellung und Austausch der Computational Essays
- Die Schüler*innen vollziehen die in den Computational Essays der anderen Gruppen dokumentierten Erkenntnis- und Programmierprozess nach.
- Die Schüler*innen bewerten die Dokumentation und den Programmcode der anderen Gruppen und entwickeln begründete Anpassungs- und Erweiterungsvorschläge.
- Teil 5: Reflexion
- Die Schüler*innen bewerten die Rolle des Programmierens und der Daten in ihren Erkenntnisprozessen.
- Die Schüler*innen beschreiben und diskutieren die Interaktion zwischen programmierender Person und digitalem Artefakt in epistemischen Programmierprozessen.
- Die Schüler*innen diskutieren die Perspektive des datengetriebenen epistemischen Programmierens und die allgemeinbildende Rolle des Programmierens im Hinblick auf Erkenntnis- und Explorationsprozesse.
- Die Schüler*innen identifizieren geeignete Anwendungsmöglichkeiten für epistemisches Programmieren Programmierprojekte und entwickeln Ideen für eigene und persönlich oder gesellschaftlich relevante datengetriebene epistemische Programmierprojekte.
Leitfragen
- Teil 1: Erarbeitung initialer Fragestellungen/Forschungsinteressen
- Wie lassen sich gute und beantwortbare statistische Fragestellungen für datengetriebene epistemische Programmierprojekte formulieren?
- Teil 2: Daten sammeln
- a) Daten mithilfe eines Messinstrumentes selbst erheben
- Wie kann eine Sensebox/ein Arduino zusammengebaut und programmiert werden, um geeignete Daten hinsichtlich der eigenen Forschungsfrage erheben zu können?
- b) Daten aus verschiedenen Quellen sammeln und zusammentragen
- Wie können geeignete Daten aus vorhandenen Datenquellen passend zur eigenen Forschungsfrage gefunden werden?
- a) Daten mithilfe eines Messinstrumentes selbst erheben
- Teil 3: Datenexploration und verwobener Erkenntnis- und Programmierprozess
- Wie können in Python und Jupyter Notebooks verschiedene Schritte im Datenexplorationsprozess ausgeführt werden (z.B. Daten einlesen, Datentypen festlegen, verschiedene Visualisierungen erstellen, …)?
- Wie können Worked Examples als Unterstützung in datengetriebenen epistemischen Programmierprojekten genutzt werden?
- Welche Aspekte muss ein Computational Essay enthalten, um epistemische Programmierprozesse nachvollziehbar und reproduzierbar zu dokumentieren?
- Teil 4: Vorstellung und Austausch der Computational Essays
- Was sind Kriterien für nachvollziehbare und reproduzierbare Computational Essays?
- Wie können Computational Essays gelesen, nachvollzogen und adaptiert/erweitert werden?
- Teil 5: Reflexion
- Welche Rolle nehmen die programmierende Person und das digitale Artefakt im Rahmen von epistemischen Programmierprozessen ein?
- Welche weiteren persönlich oder gesellschaftlich relevanten Projekte gibt es, die unter der Verwendung von Daten in epistemischen Programmierprojekten adressiert werden können?
Lesson overview
Gesamtüberblick
Abhängig von der Lernzielausrichtung sowie der zur Verfügung stehenden Zeit gibt es verschiedene Möglichkeiten, dieses Unterrichtsmodul durchzuführen. Während der Fokus im Modul auf der Durchführung einer Datenexploration liegt, kann man zuvor wahlweise eigene Daten sammeln, Daten aus verschiedenen (Online-)Quellen zusammentragen oder Wetterdaten aus dem POWER-Projekt des NASA Langley Research Center (LaRC), das durch das NASA Earth Science/Applied Science Program finanziert wird, nutzen (https://power.larc.nasa.gov/data-access-viewer/). Im letzteren Fall überspringt man dann die Datensammlungsphase und benötigt daher etwas weniger Zeit für das gesamte Unterrichtsmodul.
Grob lässt sich das Unterrichtsmodul somit in folgende Teile unterteilen:
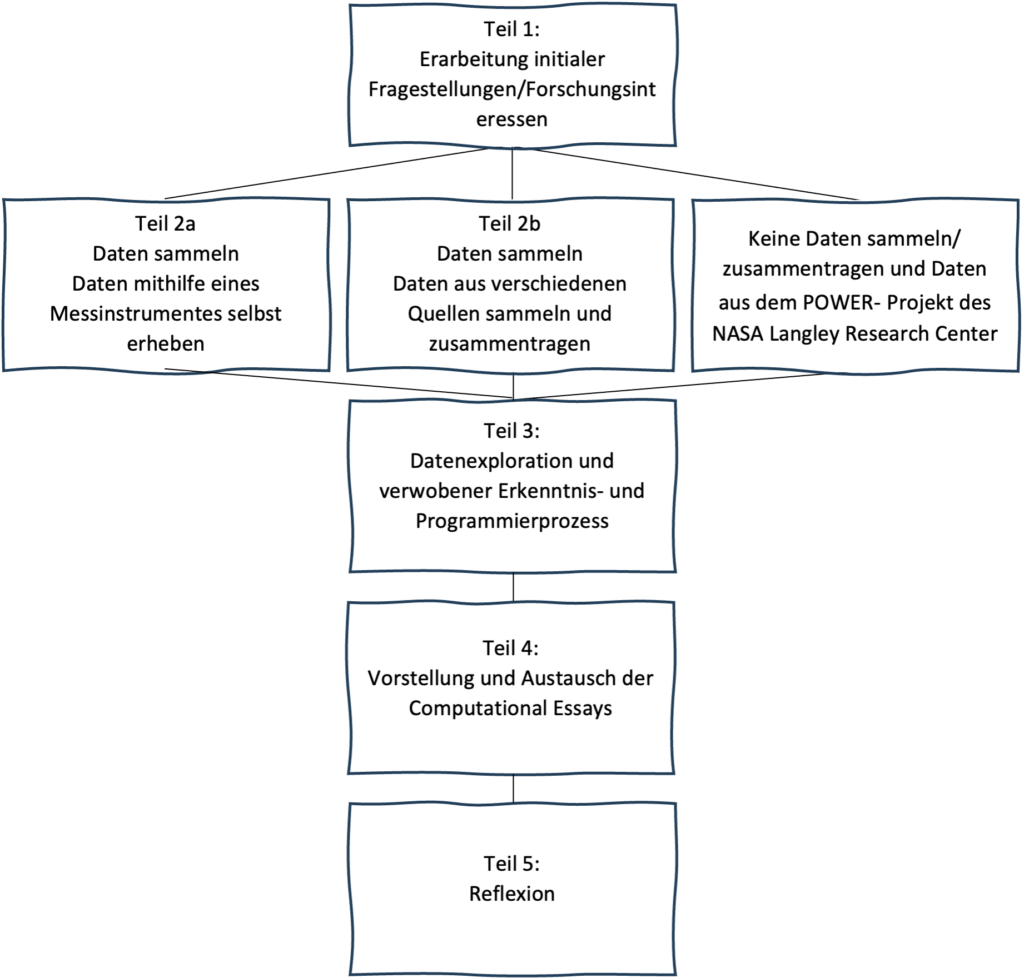
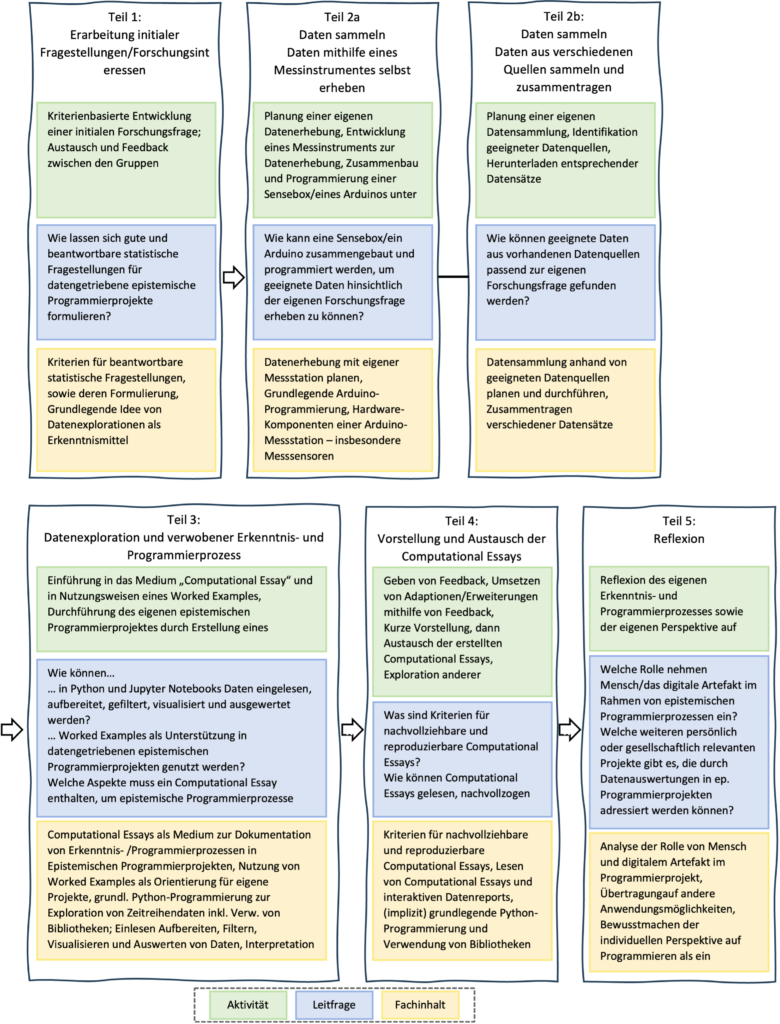
In der folgenden Graphik sieht man die jeweiligen Aktivitäten, Leitfragen und Fachinhalte der einzelnen Teile.
Teil 1: Erarbeitung initialer Fragestellungen/Forschungsinteressen
| Phase | Content | Goals | Material |
|---|---|---|---|
|
1.1 |
Einführung in den Kontext und Problematisierung: |
|
Übersicht über Texte und Artikel zum Thema „Datenbasierte Umweltanalyse“ (Uebersicht_Zeitungsartikel_Umweltfragen) |
|
1.2 |
Entwicklung einer persönlichen Fragestellung |
|
AB2_EntwicklungeinerFragestellung |
Teil 2a: Daten sammeln - Daten mithilfe eines Messinstrumentes selbst erheben
| Phase | Content | Goals | Material |
|---|---|---|---|
|
2a.1 |
Kennenlernen der Sensebox als programmierbares Messinstrument |
|
Lernkarten für die Sensebox (Link: https://sensebox.de/de/lernkarten-mcu) |
|
2a.2 |
Entwicklung einer ersten Messstation |
|
Blockprogrammierumgebung Blockly (Link: https://blockly.sensebox.de/) |
|
2a.3 |
Programmierung der Sensebox für die Datenerhebung |
|
Blockly (Link: https://docs.sensebox.de/category/blockly/) |
Teil 2b: Daten sammeln - Daten aus verschiedenen Quellen sammeln und zusammentragen
| Phase | Content | Goals | Material |
|---|---|---|---|
|
2b.1 |
Organisation der Datensammlung |
|
AB3b_Planung_Datensammlung (Seite 1) |
|
2b.2 |
Recherche zu verschiedenen Datenquellen |
|
AB3b_Planung_Datensammlung |
|
2b.3 |
Download und Abspeichern der relevanten Daten |
|
AB3b_Planung_Datensammlung (Seite 2) |
Teil 3: Datenexploration und verwobener Erkenntnis- und Programmierprozess
| Phase | Content | Goals | Material |
|---|---|---|---|
|
3.1 |
Kennenlernen der Programmierumgebung: Bevor die Schüler*innen ihre eigenen Datenexplorationsprozesse beginnen, ist es hilfreich, dass sie die Programmierumgebung (Juypter Notebooks) und die Programmiersprache (Python) erst einmal kennenlernen (siehe auch Glossar, Abschnitt 9.1). Dazu durchlaufen sie selbstständig einen Einführungskurs in Jupyter Notebooks. Dieser Kurs besteht aus insgesamt sieben Jupyter Notebooks, in denen sich die Schüler*innen mit verschiedenen wesentlichen Aspekten und Konstrukten (u.A. Variablen, Fallunterscheidungen, Wiederholungen, Funktionen, Verwendung von DataFrames) von Jupyter Notebooks und der Programmiersprache Python beschäftigen. Hinweise zur Arbeit in der Jupyter Notebook Umgebung: Beim ersten Aufruf der Jupyter Notebook Umgebung (über https://go.upb.de/ep-umweltanalyse) kann man in der Anmeldemaske einen Username und ein Passwort frei vergeben. Die bearbeiteten und ggf. neu erstellten Jupyter Notebooks bleiben dann im Account gespeichert, wenn man in den einzelnen Jupyter Notebooks auf das Speichersymbol in der Leiste klickt oder auf „File -> Save and Checkpoint“. Nach erneutem Anmelden mit dem festgelegten Username und Passwort kann man dann später wieder auf diese eigenen Dokumente zugreifen. Weitere Informationen zum Aufbau und den Inhalten der Jupyter Notebook Umgebung sind unter Abschnitt 9.1.4 zu finden. Didaktischer Kommentar: Mit den hier beschriebenen Jupyter Notebooks erarbeiten sich die Schüler*innen ein Grundwissen über die Verwendung von Jupyter Notebooks und Python als Programmiersprache. Die enthaltenen Jupyter Notebooks sollen Grundkenntnisse so weit aufbauen, dass die Schüler*innen in der nächsten Phase bereits vorhandenen Programmcode aus den Worked Examples nutzen, adaptieren und kombinieren können. Die anderen Juypter Notebooks 5-8 sind insbesondere zur vertieften Behandlung der Programmiersprache Python hilfreich und im Kontext der Umweltanalyse optional. Wichtig – insbesondere für die Phase 3.2 und 3.3 – ist es, dass sich die Schüler*innen ihre erstellten Zugangsdaten merken und ggf. auch irgendwo notieren, da sie sonst keinen Zugriff mehr auf ihre Arbeitsergebnisse haben. Zudem sollten sie innerhalb ihrer Kleingruppen darauf achten, dass sie untereinander ggf. verschiedene Arbeitsergebnisse austauschen, sodass auch bei Fehlen einer*s Schüler*in innerhalb der Gruppe weitergearbeitet werden kann. Dazu können die Schüler*innen die Jupyter Notebooks in der Menüleiste über „File -> Download as -> Notebook (ipynb)“ als ipynb-Datei herunterladen. Eine bereits heruntergeladene ipynb-Datei kann man – genau wie auch eine csv-Datei – über den Upload-Button in der Ordneransicht der Jupyter Notebook Umgebung wieder hochladen (z.B. auch unter einem anderen Account). Genauere Informationen hierzu gibt es im Glossar unter Abschnitt 9.1.5. |
|
Jupyter Notebook Umgebung Darin: Jupyter Notebooks im Unterordner Tutorial_JupyterNotebooks_Python |
|
3.2 |
Datenexplorationsprozess In dieser Phase führen die Schüler*innen in ihren Kleingruppen ihre eigenen Datenexplorationen durch, um Antworten auf ihre auf AB2 festgehaltenen Fragestellungen zu finden. Das Ziel am Ende der Phase 3.3 ist die Entwicklung eines Computational Essays (siehe auch Abschnitte 2.3, 9.1.1 und 9.4.4), also eines Dokumentes, welches den Datenexplorationsprozess abbildet und die Programmierergebnisse zusammen mit dem Programmcode sowie der Dokumentation des Erkenntnis- und Programmierprozesses darstellt. In einem Jupyter Notebook lässt sich dies am besten durch die Aufteilung des Programmcodes in einzelne Erkenntnis- und Programmierschritte erreichen, die dann in einzelnen oder ggf. auch mehreren Code-Zellen dargestellt sind und zwischen denen jeweils Erklärungen zum Code oder den aktuellen Erkenntnisschritten sowie Interpretationen der Programmierergebnisse sowie Erkenntnisse festgehalten werden können. Ein gutes Beispiel für ein Computational Essay stellen die beiden Worked Examples dar, die sich im Unterordner „Worked Examples“ befinden und ebenfalls weiter unten in dieser Phase genauer erläutert werden. Während in dieser Phase nun zunächst der Explorationsprozess an sich im Vordergrund steht, geht es in der Phase 3.3 dann um die Fertigstellung und ggf. um die Ergänzungen, um das eigene Jupyter Notebook zu einem Computational Essay zu machen. Für ihre Programmier- und Erkenntnisprozesse können die Schüler*innen wieder in derselben Jupyter Notebook-Umgebung wie in der Phase 3.1 (siehe auch Glossar, Abschnitt 9.1.4) arbeiten. Hier gibt es zwei verschiedene Arbeitsumgebungen (bzw. Unterordner), in denen die Schüler*innengruppen die Notebooks für die Durchführung ihrer Datenexploration finden: Umgebung NASA-Daten Umgebung eigene Daten Für die Durchführung ihrer eigenen Explorations- und Programmierprozesse nutzen die Schüler*innen ein Worked Example als Orientierung und gleichzeitig auch als Codebasis (siehe auch Eintrag im Glossar unter 9.1.2). Die Schüler*innen können für ihre Analyse dabei einerseits die äußere Struktur des Worked Examples übernehmen bzw. hinsichtlich der eigenen Bedürfnisse adaptieren. Andererseits können sie auch konkrete „Code-Schnipsel“ oder ganze Code-Zellen aus dem Worked Example für ihr eigenes Projekt übernehmen. Hierzu befindet sich in der Jupyter Notebook Umgebung das Worked Example „WorkedExampleCO2.ipynb“ im Unterordner „Worked Examples/Worked_Example_CO2-Messstation“. Dieses Worked Example zeigt im Kontext des Themas „CO2-Raumluftanalyse“ einen Datenexplorationsprozess entlang des PPDAC-Modells (siehe Glossar – Abschnitt 9.4.2) und geht dabei insbesondere auf die Themen „Daten einlesen“, „Daten filtern“, „Daten gruppieren“ sowie auf die Erstellung verschiedener Visualisierungsformen ein. Alternativ steht ein kürzeres Worked Example zum Thema der Wetteranalyse in London und Paderborn zur Verfügung, welches (ggf. mit weniger erklärenden Texten) aufzeigt, wie Daten eingelesen, gefiltert und in einem Scatter- oder Boxplot visualisiert werden können. Ein mögliches Vorgehen für die Schüler*innen könnte es sein, zunächst einmal die Codeschnipsel zum Einlesen der Daten aus dem Worked Example zu kopieren, in das eigene Jupyter Notebook Dokument einzufügen und an die eigenen Daten anzupassen. Anschließend könnten sie sich eine Auswertung oder eine Visualisierung aus dem Worked Example heraussuchen, von der sie sich einen ersten Überblick über den eigenen Datensatz versprechen. Auch hierzu könnten sie den Code entsprechend kopieren und anpassen. Im Anschluss an die Erstellung eines ersten Überblicks und für eine tiefergehende Analyse (zum Beispiel durch Filtern/Gruppieren der Daten) können sie sich dann vor dem Hintergrund des eigenen Erkenntnisinteresses bzw. der eigenen Forschungsfrage Anpassungen/Erweiterungen überlegen und dabei das Worked Example als „Steinbruch“ für relevanten Programmcode verwenden. Für die Analyse können die Schüler*innengruppen nun frei vorgehen und die Daten in „ihrem“ Jupyter Notebook explorieren, indem sie die Datenoperationen und Datentransformationen „Filtern“, „Visualisieren“, „Gruppieren“, „Berechnen von statistischen Kennwerten“ anwenden. Wie welche dieser Operationen und Transformationen verwendet wird, hängt immer stark vom jeweiligen Erkenntnisinteresse der einzelnen Vorhaben der Gruppen ab. Das Worked Example kann dabei eine Orientierung bieten, indem die Schüler*innen geeignete Operationen und Transformationen darin entdecken, die sie in ihrem eigenen Projekt verwenden können. Die Lehrkraft kann während dieser Phase die Gruppen bei Fragen unterstützen, sollte sich allerdings im Sinne des Lenkens der Projekte weitestgehend zurückhalten, damit die Schüler*innen eigenverantwortlich vorgehen und neue Erkenntnisse gewinnen können, was im Sinne der Entwicklung einer Epistemic Agency (siehe Abschnitt 9.4.3) ein wesentliches Ziel des gesamten Unterrichtsmoduls darstellt. Der zeitliche Rahmen für die Datenexploration ist sehr flexibel gestaltbar. Mindestens sollte man den Schüler*innengruppen zwei Doppelstunden/Lerneinheiten (2*90 Minuten) Zeit gewähren, um ihre Exploration abzuschließen. Es kann hilfreich sein, in regelmäßigen zeitlichen Abständen im Plenum eine kurze Zwischenpräsentation der einzelnen Projekte zu machen, in denen die einzelnen Schüler*innengruppen kurz berichten, was ihr aktueller Erkenntnis- und Prozessstand ist, wo ggf. Fragen oder Probleme liegen und was sie bereits gelöst/geschafft haben. Ggf. ergeben sich auf diese Weise Möglichkeiten, dass sich einzelne Gruppen untereinander austauschen oder weiterhelfen, indem sie im Anschluss an diese Zwischenpräsentationen kurz zusammenkommen und sich beraten. Didaktischer Kommentar: Um die Schüler*innen für die Durchführung ihres Datenprojektes und die Entwicklung ihres Computational Essays zu unterstützen, sollten ihnen folgende Aspekte als Vorgehensweise mit an die Hand gegeben werden: In dieser Phase ist es wichtig, dass man den Schüler*innengruppen Zeit und Raum für eine freie Exploration der Daten gibt. Es empfiehlt sich, zu Beginn der Exploration zunächst überblicksartig zu starten – z.B. mithilfe eines einfachen Scatter- oder Boxplots – und sich dann immer genauer hinsichtlich der eigenen Fragestellung in die Datenexploration zu vertiefen, wobei sich auch das Erkenntnisinteresse immer weiter verändern/konkretisieren kann. Dabei kann man jeweils auf vorausgehende Erkenntnisse aufbauen. In dieser Hinsicht könnte es hilfreich sein, dass die Schüler*innen ihre jeweiligen Erkenntnisse direkt im Jupyter Notebook festhalten und darauf aufbauend auch ihre weiteren Schritte direkt dort planen und festhalten. Auch eine Dokumentation des Programmcodes bzw. der einzelnen Code-Zellen kann bereits in dieser Phase erfolgen. Für die Erstellung eines Computational Essays (siehe Abschnitte 2.3, 9.1.1 und 9.4.4) ist dies bereits ein hilfreicher Schritt, sodass die Arbeit in der Phase 3.3 bereits hier entlastet werden kann. Die Schüler*innen sollten in dieser Phase darauf hingewiesen werden, das ausgewählte Worked Example zur Hilfe zu nehmen. Nicht nur können sie sich dabei an der äußeren Struktur orientieren, sondern können auch einzelne Code-Teile aus dem Worked Example kopieren, adaptieren und kombinieren. Insbesondere hinsichtlich der Nutzung bereits vorhandenen Programmcodes sollten Schüler*innen hier ermutigt werden. Wichtig zu erwähnen ist noch, dass die Schüler*innengruppen darauf achten sollten, dass sie ihre bearbeiteten Jupyter Notebooks hin und wieder zwischenspeichern – insbesondere bevor sie sich aus der Jupyter Notebook Umgebung abmelden. Dies funktioniert bei einem geöffneten Jupyter Notebook, indem man in der Leiste oben auf „File“ und dann „Save and Checkpoint“ klickt. |
|
Jupyter Notebook Umgebung Darin: Jupyter Notebooks im Unterordner Umgebung NASA-Daten bzw. Umgebung eigene Daten sowie Worked Examples im Unterordner Worked Examples |
|
3.3 |
Finalisieren des Computational Essays entlang des PPDAC-Kreislaufs Nachdem die Gruppen in der vorausgehenden Phase bereits verschiedene Datenoperationen und Datentransformationen ausführen konnten, wird ihnen in dieser Phase das Format eines Computational Essays nähergebracht (siehe Abschnitt 9.1.1). Basierend darauf finalisieren die einzelnen Gruppen ihre Erkenntnis- und Programmierprozesse, wobei am Ende ein Computational Essay entstehen soll. Diese Phase besteht folglich aus einem Input zu Computational Essays sowie einer Programmier-Phase, in der die einzelnen Gruppen ihre Computational Essays als Jupyter Notebooks finalisieren. Der Input zum Thema Computational Essays kann dabei anhand der Powerpoint-Folien mit dem Namen „Input_Computational_Essays“ erfolgen. In der Datei findet man dabei auch konkrete Notizen zu den einzelnen Folien, die bei der Erläuterung im Unterricht unterstützen können. In den Folien wird einerseits der PPDAC-Zyklus (siehe auch Abschnitt 9.4.2) erklärt, der einen „typischen“ Ablauf von Datenprojekten darstellt und dem die Schüler*innengruppen in diesem Unterrichtsmodul – wenn auch unbewusst – gefolgt sind. Anschließend wird der Begriff des Computational Essays geklärt, bevor dann erläutert wird, wie ein Computational Essay aufgebaut sein kann und was es beinhalten kann, wenn es nach dem PPDAC-Zyklus strukturiert ist. Zusätzlich kann auch noch einmal das Worked Example zu den CO2-Daten durchlaufen werden – entweder gemeinsam im Plenum oder individuell von den Schüler*innen (im Unterordner „Worked Examples => Worked_Example_CO2-Messstation => WorkedExample_CO2.ipynb“). Das Worked Example stellt ebenfalls ein Computational Essay dar, welches nach dem PPDAC-Zyklus aufgebaut ist und kann folglich eine gute Orientierung für die Schüler*innen hinsichtlich ihrer eigenen Jupyter Notebooks bieten. Als Unterstützung bei der Erstellung und Finalisierung des Computational Essays dient die Tabelle auf der Checkliste 2 (Computational Essay). In dieser Tabelle ist für die einzelnen Schritte des PPDAC-Zyklus‘ eingetragen, was in einem entsprechenden Computational Essay integriert werden sollte. Die Gruppe kann diese Tabelle nutzen und jeweils in der Spalte „Erledigt“ abhaken, welche Aspekte sie bereits beachtet hat für ihr eigenes Computational Essay. Didaktischer Kommentar: Das Ziel am Ende dieser Phase sollte sein, dass die Schüler*innengruppen ein strukturiertes Computational Essay erstellt haben, welches dann anderen Schüler*innengruppen oder auch Personen außerhalb des Kurses, die sich für die behandelten Forschungsfragen der Schüler*innen interessieren, zugänglich gemacht werden kann. Im Computational Essay sollte der Erkenntnis- und Programmierprozess nachvollziehbar und reproduzierbar dargestellt werden, sodass Lesende des Computational Essays damit interagieren oder es erweitern/verändern können. Dazu kann der PPDAC-Zyklus eine gute Struktur für den Aufbau des Computational Essays darstellen. Wie auch im Foliensatz auf Folie 12 gezeigt, können so verschiedene Aspekte von der Problembeschreibung bis hin zur Schlussfolgerung im Computational Essay beleuchtet werden, sodass sich eine kohärente Struktur für die Erläuterung des Erkenntnis- und Programmierprozess ergibt. Natürlich kann auch ein anderes Modell als der PPDAC-Zyklus genutzt werden. Allerdings stellt dieser im Kontext dieses Unterrichtsmoduls einen passenden „roten Faden“ dar, der direkt auf den Ablauf des Datenexplorationsprozesses der Schüler*innengruppen angewandt werden kann. Die Tabelle der Checkliste 2 (Computational Essay) bietet für die Schüler*innengruppen eine Orientierungshilfe für die Erstellung und Finalisierung des Computational Essays. Hier sollen sie zunächst in der grau unterlegten Spalte abhaken, wenn sie einen Aspekt für ihr Computational Essay beachtet haben. Die in der Tabelle aufgelisteten Aspekte können natürlich auch entsprechend des konkreten Programmierprojektes adaptiert oder erweitert werden. [1] Zu dieser Debatte gibt es einen interessanten Artikel von Rule et al. (2018), der sich mit unterschiedlichen Perspektiven auf des Erstellens von Jupyter Notebooks hinsichtlich der grundlegenden Ideen „Explorieren“ und „Erklären“ in Jupyter Notebooks auseinandersetzt. |
|
Powerpointfolien zum Computational Essay und zum PPDAC-Zyklus (Input_Computational_Essays) Jupyter Notebook Umgebung Darin: Jupyter Notebooks im Unterordner Umgebung NASA-Daten bzw. Umgebung eigene Daten sowie Worked Examples im Unterordner Worked Examples Checkliste Computational Essay: Checkliste_Computational_Essay |
Teil 4: Vorstellung und Austausch der Computational Essays
| Phase | Content | Goals | Material |
|---|---|---|---|
|
4.1 |
Austausch der Computational Essays in verschiedenen Gruppen |
|
Checkliste Computational Essay: Checkliste_Computational_Essay |
|
4.2 |
Einarbeiten von Feedback für das eigene Computational Essay |
|
Checkliste Computational Essay: Checkliste_Computational_Essay |
|
4.3 |
Vorstellung der Computational Essays |
|
AB4_Praesentation |
Teil 5: Reflexion
| Phase | Content | Goals | Material |
|---|---|---|---|
|
5.1 |
Reflexion des Erkenntnis- und Programmierprozesses |
|
AB5_Reflexion |
Arbeit mit Jupyter Notebooks und Jupyter Notebook Umgebung
In diesem Unterrichtsmodul werten die Schüler*innen zuvor erhobene oder gesammelte Daten in Jupyter Notebooks aus. Die Jupyter Notebook Umgebung bezeichnet eine webbasierte, interaktive Plattform, auf der Nutzende programmierbasierte Narrative erstellen können, die Live-Code, erläuternden Text, interaktive Elemente und andere Medien beinhalten können (siehe Perez & Granger, 2015, S. 2). Die Dokumente, die Nutzende erstellen können, sogenannte Jupyter Notebooks, bestehen aus Code- und Markdown-Zellen, die untereinander angeordnet sind. Die Nutzenden können Code in die Code-Zellen schreiben, dessen Output beim Ausführen des Codes direkt unter der Codezelle angezeigt werden kann. Durch die Nutzung mehrerer Code-Zellen kann man so den gesamten Programmcode aufteilen und sich Zwischenergebnisse anzeigen lassen. Zusätzlich kann man in den Markdown-Zellen Kommentare hinzufügen, beispielsweise um den Programmcode zu dokumentieren.
Ein Beispiel für ein Jupyter Notebook findet man hier: https://jupyter.org/try-jupyter/notebooks/?path=notebooks/Intro.ipynb(Aufruf am 20.11.2024; Hinweis: Nach Aufrufen des Links muss man zunächst oben in die leere Zelle auf der Seite klicken, um das Notebook zu aktivieren.)
Ein Vorteil, den die Verwendung von Jupyter Notebooks für die Arbeit in der Schule bietet, ist, dass Lehrkräfte bereits vorgefertigte Jupyter Notebooks zur Verfügung stellen können, in denen beispielsweise schon Programmcode (aus verschiedenen Bibliotheken) vorhanden ist. Die Schüler*innen können dann auf diesem Programmcode aufbauen und ihn hinsichtlich eigener Interessen erweitern. Auch kann ein Jupyter Notebook wie ein digitales Arbeitsblatt genutzt werden, indem Lehrkräfte Aufgabenstellungen in das Jupyter Notebook (als Markdown-Zellen) schreiben. Die Schüler*innen können die Aufgabenstellungen dann in (ggf. vorbereiteten oder schon teilweise ausgefüllten) Codezellen bearbeiten.
Weitere Informationen über Jupyter Notebooks findet man in der Dokumentation unter https://docs.jupyter.org/en/latest/(Aufruf am 20.11.2024)
Computational Essays als Programmierprodukte
Ein Computational Essay bezeichnet ein interaktives Dokument, welches erläuternden Text, kleine Programme oder Programmschnipsel und Outputs beinhaltet, um Ergebnisse einer Untersuchung zu präsentieren oder eigene Ideen auszudrücken (siehe Atkinson et al., 2000; Odden & Malthe-Sørenssen, 2021; Wolfram, 2017). Ein Computational Essay kann folglich dazu genutzt werden, den Programmierprozess verständlich darzustellen, sodass Lesende nachvollziehen können, wie man zu den Ergebnissen und Schlussfolgerungen gelangt ist (siehe auch Hüsing & Podworny, 2022). Gleichzeitig können Leser*innen eines Computational Essays mit den Inhalten oder dem Code interagieren und auf diese Weise den Programmierprozess eigenständig weiter/tiefer explorieren.
Im Kontext der Datenexploration stellen Computational Essays ein geeignetes Mittel dar, um den verwobenen Datenexplorations- und Programmierprozess festzuhalten und zu dokumentieren. In einem Computational Essay kann die Auswertung Schritt für Schritt erklärt werden und gleichzeitig können die Programmierergebnisse wie Visualisierungen oder die berechneten Kennwerte beschrieben und interpretiert werden. Die Verwendung von Jupyter Notebooks und die Unterteilung in viele Programmier- und Markdownzellen ist hierzu sehr gut geeignet.
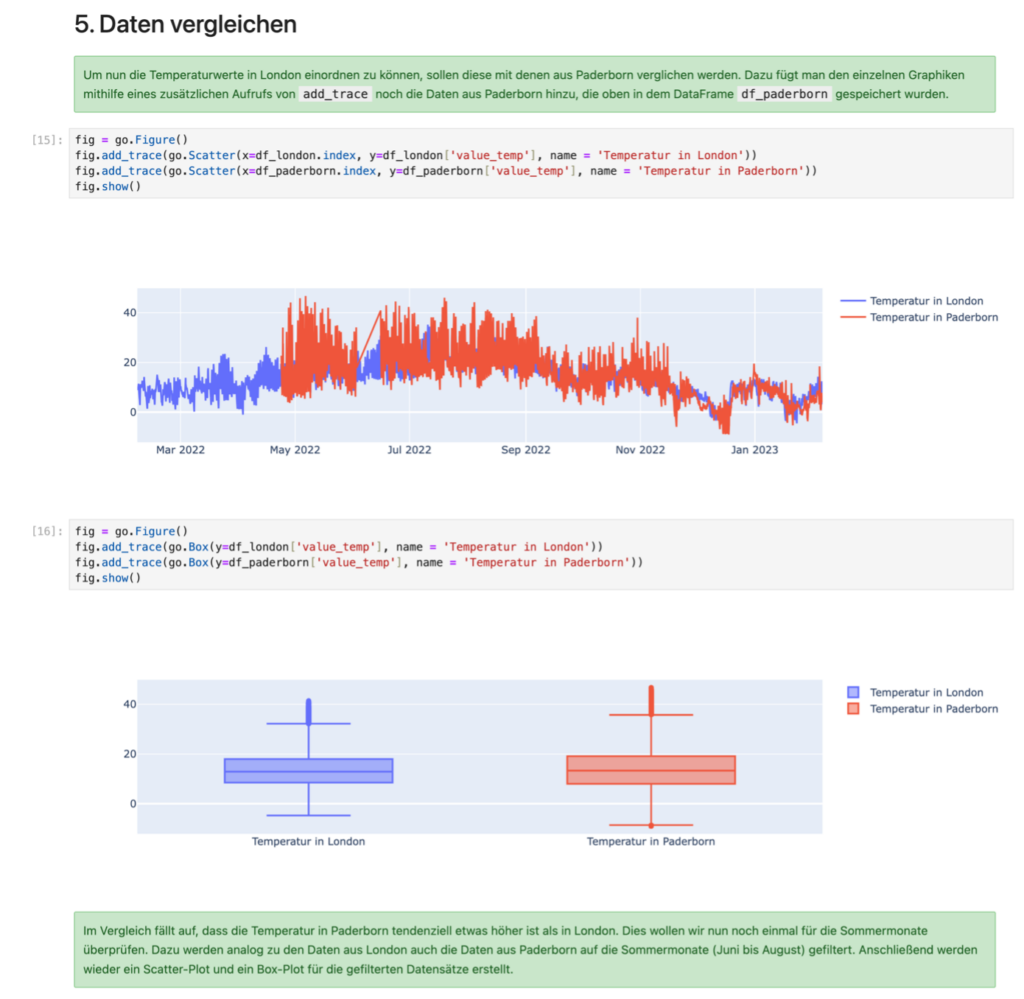
Nachfolgend sieht man einen Ausschnitt eines beispielhaften Computational Essays, in dem ein Vergleich der Temperatur in London und Paderborn gezeigt wird. In den grünen Zellen befindet sich eine Erklärung zu dem genutzten Programmcode sowie eine (kurze) Interpretation der beiden dargestellten Graphiken.
Worked Examples als Unterstützung beim Programmieren nutzen
Ein Worked Example bezeichnet ein vollständig ausgearbeitetes und dokumentiertes Beispiel zu einem ähnlichen Projekt, wie dem, was gerade betrachtet und angegangen wird (siehe Atkinson et al., 2000; Muldner et al., 2023). Es kann als Quelle für Inspiration und als Orientierung genutzt werden – insbesondere, wenn man noch wenig Erfahrung im Kontext des Projektes hat. Im Kontext des Programmierens können Worked Examples überdies als „Steinbruch“ für Programmcode dienen, indem Lernende den Programmcode aus einem Worked Example zunächst kopieren, dann an die eigenen Bedürfnisse bzw. an das eigene Projekt anpassen und anschließend erweitern (siehe auch „Use-Modify-Make“ in Lee et al., 2011 sowie Hüsing et al., 2024). Hier eignen sich vor allem Computational Essays als Format für ein Worked Example, um den Programmierprozess für Lernende transparent zu machen und aufzuzeigen, wie die Programmierschnipsel genutzt werden können.
Im Rahmen dieses Unterrichtsmoduls gibt es zwei Worked Examples, welche die Schüler*innen dabei unterstützen können, eigene Explorationen von Umweltdaten durchzuführen. Im Worked Example zur CO2-Analyse wird exemplarisch gezeigt, wie sich CO2-Daten im Zusammenhang mit anderen Größen analysieren lassen. Darüber hinaus wird im Worked Example zur Wetteranalyse gezeigt, wie sich Wetterdaten verschiedener Orte explorieren lassen. Lernende können diese Worked Examples als Orientierung oder „Code-Steinbruch“ für ihre eigenen Umweltdatenprojekte nutzen.
Zugriff auf die Jupyter Notebook-Umgebung für diese Unterrichtsreihe (Erstellen eines Accounts und Login)
Für die Phase der Datenanalyse steht für dieses Unterrichtsmodul eine vorbereitete Jupyter Notebook Umgebung zur Verfügung. Diese kann über den folgenden Link aufgerufen werden: https://go.upb.de/ep-umweltexploration
Beim ersten Öffnen dieses Links müssen sich die Schüler*innen einen eigenen Account erstellen. Dazu geben sie in die Anmeldemaske einen Benutzernamen und ein Passwort ein. Beides können sie sich frei überlegen. Wichtig ist nur, dass sie sich beides merken, um den Arbeitsfortschritt im eigenen Account immer wieder abrufen zu können. Dazu können sie sich später mit ihren bei der ersten Anmeldung vergebenen Daten wieder unter dem gleichen Link anmelden.
Aufbau und Inhalte der Jupyter Notebook Umgebung
In der Jupyter Notebook Umgebung finden sich verschiedene Jupyter Notebooks, die von den Schüler*innen im Unterrichtsmodul verwendet werden können. Nach dem Einloggen in die Umgebung gelangt man zu einer Ordner-Übersicht. Jeder Ordner (bis auf den res-Ordner) stellt dabei eine separate Umgebung dar, auf die im Folgenden kurz eingegangen wird.
- Cheatsheets
- Cheatsheet Datenexploration in Jupyter Notebooks mit Python.ipynb
Cheatsheet, welches wesentliche Python-Befehle und Codeschnipsel zur Datenexploration in Jupyter Notebooks zeigt und kurz erläutert; Schüler*innen können dieses Cheatsheet als Hilfestellung während ihrer eigenen Datenexplorationen nutzen
- Cheatsheet Datenexploration in Jupyter Notebooks mit Python.ipynb
- Tutorial_JupyterNotebooks_Python
Dieser Ordner enthält mehrere Tutorial-Jupyter-Notebooks, die in die Verwendung von Jupyter Notebooks mit der Programmiersprache Python einführen. Die Jupyter Notebooks können dabei individuell durchlaufen und bearbeitet werden.- 0_Start.ipynb
- 1_Erste_Schritte.ipynb
- 2_Python_Basics. ipynb
- 3_Fallunterscheidungen.ipynb
- 4_Wiederholungen.ipynb
- 5_Funktionen.ipynb
- 6_DataFrames.ipynb
- Umgebung eigene Daten
Dieser Ordner enthält die Umgebung für die Exploration eigener Daten, die entweder selbst erhoben (siehe Phase 2a der Unterrichtsreihe) oder aus verschiedenen Quellen gesammelt und zusammengetragen wurden (siehe Phase 2b der Unterrichtsreihe).- Computational_Notebook.ipynb
Jupyter Notebook, in dem die Schüler*innen ihre eigene Datenanalyse durchführen können; enthält bereits den Import der wesentlichen Biblio-theken sowie die Aufgabenstellung/Einführung - Eigene_Basisinformationen.ipynb
Jupyter Notebook, in dem Basisinformationen über die Daten (u.A. Mess-methoden/Herkunft etc.) festgehalten werden können. - Messprotokoll.ipynb
Jupyter Notebook, in dem Informationen über die Messung und das Messprotokoll festgehalten werden kann, falls die Schüler*innen eigene Daten erhoben haben - Tutorial_Daten_einlesen.ipynb
Kurzes Tutorial, in dem erklärt wird, wie eigene Daten in die Jupyter Notebook Umgebung geladen werden können
- Computational_Notebook.ipynb
- Umgebung NASA-Daten
Dieser Ordner enthält die Umgebung für die Exploration der Daten aus dem POWER-Projekt des NASA Langley Research Center (LaRC), das durch das NASA Earth Science/Applied Science Program finanziert wird.- Computational_Notebook_NASA-Data.ipynb
Notebook, in dem Schüler*innen verschiedene Wetterdaten zu beliebigen Orten und für beliebige Zeiträume direkt in das Jupyter Notebook laden und dort analysieren können; Folgende Wetterdaten können in das Jupyter Notebook geladen werden:- Luftfeuchtigkeit in %
- Niederschlag in mm/Stunde
- Temperatur in °C
- Windgeschwindigkeit in m/s
- Computational_Notebook_NASA-Data_Beispielvisualisierungen.ipynb
Jupyter Notebook, in dem anhand von Beispielen gezeigt wird, wie bestimmte Visualisierungen mit den „NASA-Daten“ erstellt werden können
- Computational_Notebook_NASA-Data.ipynb
- Worked Examples
Dieser Ordner enthält 2 verschiedene ausgearbeitete Beispielprojekte zur Exploration von Umweltdaten. Das Projekt wird dabei jeweils als ein Worked Example dargestellt, welches die Lernenden nutzen können, um sich daran zu orientieren oder auch, um einzelne Codeschnipsel zu nutzen/adaptieren/erweitern.
- Worked_Example_CO2-Messstation
- Basisinformationen.ipynb
Jupyter Notebook, in dem wesentliche Informationen zur Datenmessung festgehalten sind - WorkedExample_CO2.ipynb
Jupyter Notebook, in dem exemplarisch eine Exploration von CO2-Daten im Klassenraum gezeigt wird
- Basisinformationen.ipynb
- Worked_Example_Wetterdaten
- WorkedExample_Wetterdaten.ipynb
Jupyter Notebook, in dem exemplarisch eine Exploration von Wetterdaten (aus London und Paderborn) gezeigt wird, wobei eigene Daten als csv-Datei eingelesen und aufbereitet werden - WorkedExample_Wetterdaten_NASA.ipynb
Ähnliches Jupyter Notebook zur Exploration von Wetterdaten aus London und Paderborn, mit dem Unterschied, dass hier Daten aus dem POWER-Projekt des NASA Langley Research Center (LaRC) (s.o.) genutzt werden. Hier wird auch gezeigt, wie die Daten des POWER-Projekts heruntergeladen und eingelesen werden können.
- WorkedExample_Wetterdaten.ipynb
- Worked_Example_CO2-Messstation
Hinweis: Die Ordner mit den Namen „res“ oder „Daten“ enthalten Dateien (RESsourcen) wie Bilder und Daten, die in den Jupyter Notebooks verwendet werden, auf die aber nicht direkt über die Ordnerstruktur zugegriffen werden muss.
Herunterladen der eigenen Jupyter Notebooks und Hochladen von fremden Jupyter Notebooks (beispielsweise von anderen Gruppen)
Hier im Unterrichtsmodul sollen die Gruppen in Phase 4 ihre erstellten Jupyter Notebooks austauschen und sich gegenseitig Feedback dazu geben. Auch in anderen Situationen kann es sinnvoll sein, die Jupyter Notebooks untereinander auszutauschen, beispielsweise, wenn die Jupyter Notebooks präsentiert werden sollen und sich interessierte die erstellten Jupyter Notebooks angucken. In diesen Fällen müssen die Jupyter Notebooks aus der Jupyter Notebook Umgebung heruntergeladen werden. Später können sie dann im Account einer anderen Person wieder hochgeladen werden.
Herunterladen eines Jupyter Notebooks
Um ein Jupyter Notebook aus der Jupyter Notebook Umgebung herunterzuladen, gibt es mehrere Möglichkeiten. Entweder man lädt das Jupyter Notebook herunter, wenn es geöffnet ist oder man lädt es aus der Ordneransicht herunter.
Wenn man das aktuell geöffnete Jupyter Notebook herunterladen möchte, klickt man oben in der Liste auf „File“ und dann auf „Download“. Das Jupyter Notebook wird dann als ipynb-Datei heruntergeladen.
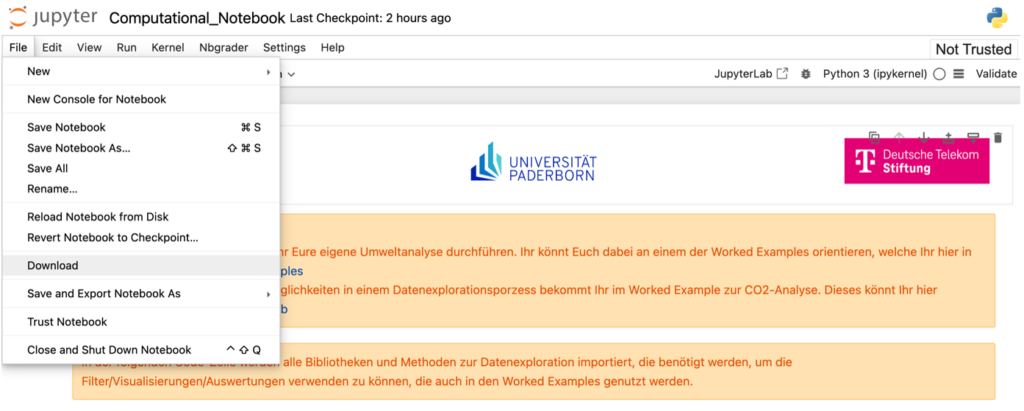
Alternativ kann man das Jupyter Notebook auch aus der Ordneransicht herunterladen. Dazu klickt man den Haken neben dem herunterzuladenen Jupyter Notebook an und klickt dann oben in der Leiste auf „Download“. Ebenfalls kann man hier auch mehrere Dateien auf einmal herunterladen, indem man den Haken neben mehreren Dateien aktiviert und anschließend auf „Download“ klickt.
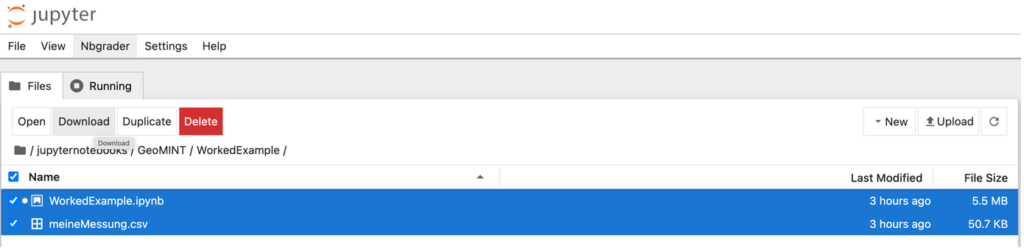
Wichtiger Hinweis:
Damit das Jupyter Notebook auch in einem anderen Account geöffnet werden kann, ist es wichtig, alle Daten und Ressourcen, wie Bilder, herunterzuladen und später wieder in derselben Ordnerstruktur hochzuladen. Liegt also beispielsweise eine Datei „data.csv“ in einem Unterordner „Daten“, so muss in dem neuen Account ebenfalls ein solcher Unterordner erstellt werden, in den dann die Datei „data.csv“ hochgeladen wird.
Hochladen eines Jupyter Notebooks
Um ein heruntergeladenes Jupyter Notebook in einem anderen Account wieder hochzuladen, klickt man in der Ordneransicht auf den Button „Upload“. Anschließend wählt man alle Dateien aus, die man hochladen möchte. Die Dateien sollten dann direkt im Ordner erscheinen. Per Drag&Drop oder durch einen Rechtsklick auf einzelne oder mehrere ausgewählte Dateien kann man sie auch in andere Ordner kopieren bzw. verschieben.
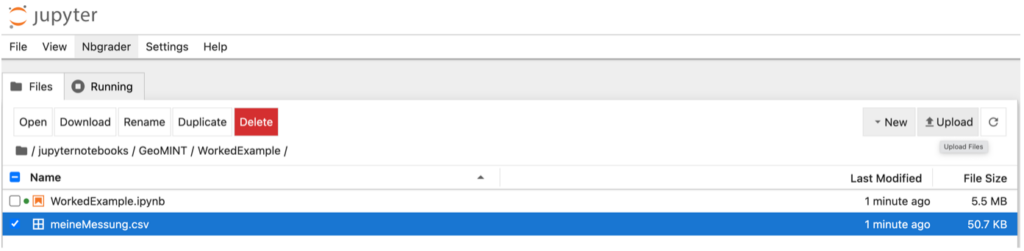
Wichtiger Hinweis:
Damit das hochgeladene Jupyter Notebook korrekt funktioniert, müssen auch alle Ressourcen, auf die das Jupyter Notebook Zugriff haben muss (wie z.B. Daten oder Bilder) in derselben Ordnerstruktur wie zuvor hochgeladen werden. Liegt also beispielsweise eine Datei „data.csv“ in einem Unterordner „Daten“, so muss in dem neuen Account ebenfalls ein solcher Unterordner erstellt werden, in den dann die Datei „data.csv“ hochgeladen wird.
Export eines Jupyter Notebooks als HTML-Datei
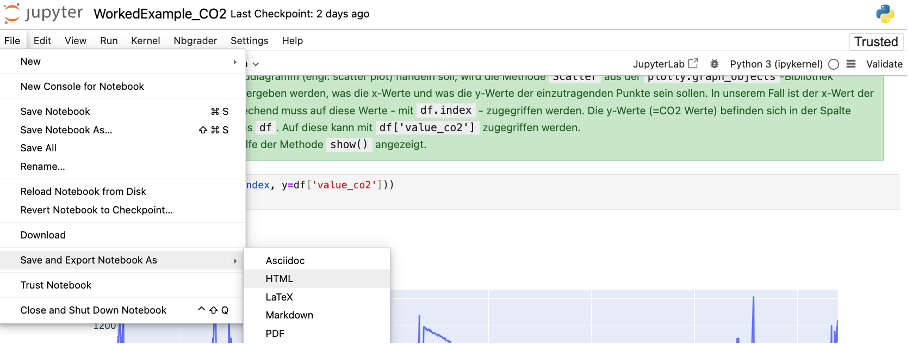
Um ein Jupyter Notebook für eine breitere Öffentlichkeit zugänglich zu machen, kann man es als HTML-Datei exportieren. Dies bietet den Vorteil, dass der Programmcode zwar nicht mehr verändert werden kann, die Programmierergebnisse aber noch immer interaktiv sind. Insbesondere kann man beispielsweise in entwickelte Visualisierungen herein und herauszoomen. Die HTML-Datei kann man beispielsweise nutzen, um das Computational Essay der Lernenden auf der eigenen Homepage zu veröffentlichen und so über die ggf. auch lokalgesellschaftlich relevanten Erkenntnisse der Lernenden nachvollziehbar und transparent zu informieren.
Um ein Jupyter Notebook als HTML-Datei zu exportieren, öffnet man das Jupyter Notebook und klickt dann auf „File => Save and Export Notebook As => HTML“. Die dann heruntergeladene Datei kann man in beliebigen Browsern öffnen. Dort wird dann das Jupyter Notebook entsprechend angezeigt und man kann mit den Programmierergebnissen interagieren. Zugleich kann man den Code aus der HTML-Datei nutzen, um das erstellte Computational Essay beispielsweise auf der Schulhomepage anzuzeigen.
Arbeit mit der Sensebox und der OpenSenseMap
Die Sensebox
Die Sensebox ist ein programmierbares Messinstrument, mit dem eigene Daten gesammelt und gespeichert werden können. Sie besteht aus einem Mikrocomputer, an den verschiedene Messsensoren angeschlossen werden können, um Daten zu erhoben. Die Daten können dabei über eine SD-Karte oder über die OpenSenseMap (mithilfe eines WiFi- oder LoRaWan-Moduls) übertragen werden.
Die Programmierung der Sensebox kann wahlweise mithilfe der blockbasierten Sprache Blockly
oder mit der Arduino IDE (textbasierte Programmierung) erfolgen.
- Informationen zu Blockly: https://docs.sensebox.de/docs/boards/mcu/mcu-erster-sketch
- Informationen zur Arduino IDE: https://docs.sensebox.de/docs/category/arduino
Hier gibt es weitere Informationen zur Sensebox: https://docs.sensebox.de/
Die OpenSenseMap
Die OpenSenseMap ist eine Plattform, auf der man die eigene Sensebox registrieren kann, um Daten an die Plattform zu schicken (via WiFi- oder LoRaWan-Modul auf der Sensbox), zu sammeln und zu veröffentlichen. Gleichzeitig hat man über die Plattform Zugriff auf die Daten aller weltweit registrierten Senseboxen. Auf diese Weise lassen sich Datensätze als csv-Dateien von verschiedenen Standorten auf der Welt herunterladen und für die eigene Auswertung nutzen.
Weitere Informationen zur OpenSenseMap: https://sensebox.de/de/opensensemap
Arbeit mit den Daten aus dem POWER-Projekt des NASA Langley Research Center (LaRC)
In der „Umgebung NASA-Daten“ können Schüler*innen Wetterdaten von überall auf der Welt direkt in ihre Jupyter Notebooks laden. Die Daten stammen aus dem POWER-Projekt des NASA Langley Research Center (LaRC), das durch das NASA Earth Science/Applied Science Program finanziert wird (https://power.larc.nasa.gov/data-access-viewer/). Auf der Website lassen sich neben den Daten über Temperatur, Luftfeuchtigkeit, Niederschlag und Windgeschwindigkeit noch viele weitere Daten in verschiedenen Dateiformaten herunterladen. Diese können beispielsweise dann auch in der „Umgebung eigene Daten“ hochgeladen werden.
Hier findet man weitere Informationen über das POWER-Projekt: https://power.larc.nasa.gov/docs/
Hinweis: Das POWER-Projekt bittet freundlich um einen Verweis, einen Weblink und/oder einen Abdruck von veröffentlichten Papieren oder Berichten oder eine kurze Beschreibung anderer Verwendungszwecke (z. B. Poster, mündliche Präsentationen usw.) von Datenprodukten, die sie bereitgestellt/ermöglicht haben. Dies hilft ihnen, die Verwendung der Daten zu bestimmen, was für die Optimierung der Produktentwicklung hilfreich ist. Es hilft ihnen auch, den Wert für die Gemeinschaft zu beurteilen. Für weitere Informationen zur Einsendung von Referenzmaterial wenden Sie sich gerne an das POWER Project Team: larc-power-project@mail.nasa.gov
Materials
Download of all materials
Here you can download an overview of the series of lessons, all worksheets, instructions and presentations as a compressed folder:
Zum Teil 1: Aufbau und Funktionsweise des Mobilfunknetzes
- Download: Folien Gedankenexperiment (für Phase 1a)
- Link: Erklärvideo zum Mobilfunknetz (Phase 1b)
- Download: Druckvorlage für das Puzzle (für Phase 1b)
- Download: Arbeitsblatt 1 (für Phase 1b)
- Download: Arbeitsblatt 2 für Niveaustufe 1 (für Phase 1b)
- Download: Arbeitsblatt 2 für Niveaustufe 2 (für Phase 1b)
- Download: Sprinteraufgabe für Arbeitsblatt 2 (für Phase 1b)
- Download: Arbeitsblatt 3 (für Phase 1b)
Glossar
Epistemic programming
Epistemisches Programmieren (Hüsing et al., 2023) bezeichnet einen erkenntniszentrierte Programmierpraktik, bei der Programmieren als Mittel zum Erkenntnisgewinn hinsichtlich persönlich oder gesellschaftlich relevanter Phänomene oder Fragestellungen genutzt wird. Ein typisches Beispiel für ein epistemisches Programmierprojekt ist die Durchführung einer Datenexploration zur Untersuchung eines Kontextes, der durch Daten abbildbar ist. Um epistemisches Programmieren als Praktik zu erlernen, bietet sich die Durchführung projektbasierten Unterrichts an, in dem Lernende in einer vorbereiteten Umgebung Programmieren nutzen, um sich in einem tüftelartigen Prozess einer eigenen Fragestellung zu nähern. Computational Essays (siehe auch Abschnitte 2.3, 9.1.1 und 9.4.4) bieten sich hier sowohl als angestrebte Produkte als auch als sogenannte Worked Examples (siehe auch Abschnitte 2.4, 9.1.2 und 9.4.5) an, um den Erkenntnis- und Programmierprozess besonders für Programmiernoviz*innen zu unterstützen.
PPDAC-Zyklus
Der PPDAC-Zyklus (Wild & Pfannkuch, 1999)ist ein Modell zur Durchführung von Datenprojekten und ist in die Phasen „Problem“, „Plan“, „Data“, „Analysis“ und „Conclusions“ unterteilt. Diese Phasen können dabei zyklenartig nacheinander durchlaufen und wiederholt werden.
- In der Problem-Phase geht es darum, das Problem genauer einzugrenzen und zu definieren.
- In der Plan-Phase wird die Datenerhebung und -auswertung geplant.
- In der Data-Phase erfolgt die Datensammlung, das Datenmanagement und die Datenbereinigung.
- In der Analysis-Phase werden die Daten exploriert und darauf aufbauend Ergebnisse und Hypothesen generiert.
- In der Conclusions-Phase wird eine Interpretation der Ergebnisse vorgenommen und es werden Schlussfolgerungen und neue Ideen generiert.
Epistemic Agency
Das Konstrukt Epistemic Agency bezieht sich auf die Befähigung, Wissen und Wissenspraktiken einer Community mit zu bestimmen (Miller et al., 2018; Stroupe, 2014) bzw. kognitive Kontrolle und Verantwortung über das eigene Lernen zu übernehmen (Odden et al., 2023). Lernende können folglich Epistemic Agency erlangen, indem sie aktiv in Wissens- und Erkenntnisprozesse eingebunden werden und indem ihnen Freiheiten zum eigenständigen Erkunden persönlich oder gesellschaftlich relevanter Interessen gegeben wird. Miller et al. (2018) geben hierzu vier Möglichkeiten an, um die Epistemic Agency in Lernenden zu fördern:
- Das Wissen der Schüler*innen als Ressource für das Lernen nutzen und darauf aufbauen
- Lernende Wissen aktiv entwickeln lassen
- Wissen aufbauen, das für die Schüler*innen nützlich ist (z.B. durch authentische Fragestellungen)
- Lernen und Wissen nutzen um Veränderungen von Strukturen oder Handlungen initiieren
Computational Essay
Ein Computational Essay lässt sich als ein ausformuliertes Essay beschreiben, welches neben textuellen Beschreibungen, Interpretationen und Erläuterungen insbesondere auch manipulierbaren Programmcode enthält, der direkt im Medium ausgeführt werden kann (DiSessa, 2000; Odden et al., 2023; Wolfram, 2017).
Worked Examples
Im Kontext des Epistemischen Programmierens bezeichnet ein Worked Example ein ausgearbeitetes und dokumentiertes Programmier-Beispiel, in welchem Prozesse und Methoden angewandt werden, die für das Programmierprojektes der Schüler*innen nützlich sein könnten (Atkinson et al., 2000; Hüsing et al., 2024b; Muldner et al., 2023). Lernende können ein Worked Example einerseits als Orientierung für den eigenen Programmierprozess verwenden als auch als „Steinbruch“, aus dem sie Code verwenden, adaptieren und erweitern können (siehe auch Lee et al. (2011) und Sentance et al. (2019)).
Zeitreihendaten
Zeitreihendaten bezeichnen Daten, die wiederholt über einen bestimmten Zeitraum erhoben wurden. Für jeden erhobenen Wert wird auch der Zeitpunkt der Erhebung festgehalten. Zeitreihendaten ermöglichen es so, einen zeitlichen Verlauf der erhobenen Werte analysieren zu können. Beispielsweise können die Daten in einem Scatterplot dargestellt werden:

Literatur
- Atkinson, R. K., Derry, S. J., Renkl, A., & Wortham, D. (2000). Learning from Examples: Instructional Principles from the Worked Examples Research. Review of Educational Research, 70(2), 181–214. https://doi.org/10/csm67w
- DiSessa, A. A. (2000). Changing minds: Computers, learning, and literacy. MIT Press.
- Hüsing, S., & Podworny, S. (2022). Computational Essays as an Approach for Reproducible Data Analysis in lower Secondary School. Proceedings of the IASE 2021 Satellite Conference. IASE 2021 Satellite Conference: Statistics Education in the Era of Data Science. https://doi.org/10/gqv58h
- Hüsing, S., Schulte, C., Sparmann, S., & Bolte, M. (2024a). Using Worked Examples for Engaging in Epistemic Programming Projects. Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1 (SIGCSE 2024). Technical Symposium on Computer Science Education (SIGCSE TS), New York, NY, USA. https://doi.org/10.1145/3626252.3630961
- Hüsing, S., Schulte, C., Sparmann, S., & Bolte, M. (2024b). Using Worked Examples for Engaging in Epistemic Programming Projects. Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1, 443–449. https://doi.org/10.1145/3626252.3630961
- Hüsing, S., Schulte, C., & Winkelnkemper, F. (2023). Epistemic Programming. In S. Sentance, E. Barendsen, N. R. Howard, & C. Schulte (Eds.), Computer Science Education: Perspectives on Teaching and Learning in School (2nd ed., pp. 291–304). Bloomsbury Academic; Bloomsbury Collections. http://dx.doi.org/10.5040/9781350296947.ch-022
- Lee, I., Martin, F., Denner, J., Coulter, B., Allan, W., Erickson, J., Malyn-Smith, J., & Werner, L. (2011). Computational thinking for youth in practice. ACM Inroads, 2(1), 32–37. https://doi.org/10/ggdnzr
- Miller, E., Manz, E., Russ, R., Stroupe, D., & Berland, L. (2018). Addressing the epistemic elephant in the room: Epistemic agency and the next generation science standards. Journal of Research in Science Teaching, 55(7), 1053–1075. https://doi.org/10.1002/tea.21459
- Muldner, K., Jennings, J., & Chiarelli, V. (2023). A Review of Worked Examples in Programming Activities. ACM Transactions on Computing Education, 23(1), 1–35. https://doi.org/10.1145/3560266
- Odden, T. O. B., & Malthe-Sørenssen, A. (2021). Using computational essays to scaffold professional physics practice. European Journal of Physics, 42(1). https://doi.org/10/gjf7nq
- Odden, T. O. B., Silvia, D. W., & Malthe-Sørenssen, A. (2023). Using computational essays to foster disciplinary epistemic agency in undergraduate science. Journal of Research in Science Teaching, 60(5), 937–977. https://doi.org/10.1002/tea.21821
- Perez, F., & Granger, B. E. (2015). Project Jupyter: Computational Narratives as the Engine of Collaborative Data Science. Jupyter Blog. https://blog.jupyter.org/project-jupyter-computational-narratives-as-the-engine-of-collaborative-data-science-2b5fb94c3c58
- Rule, A., Tabard, A., & Hollan, J. D. (2018). Exploration and Explanation in Computational Notebooks. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–12. https://doi.org/10/gfw4vk
- Sentance, S., Waite, J., & Kallia, M. (2019). Teaching computer programming with PRIMM: A sociocultural perspective. Computer Science Education, 29(2–3), Article 2–3. https://doi.org/10/ggdpcg
- Stroupe, D. (2014). Examining Classroom Science Practice Communities: How Teachers and Students Negotiate Epistemic Agency and Learn Science‐as‐Practice. Science Education, 98(3), 487–516. https://doi.org/10.1002/sce.21112
- Wild, C. J., & Pfannkuch, M. (1999). Statistical Thinking in Empirical Enquiry. International Statistical Review, 67(3), 223–248. https://doi.org/10/fdhtmj
- Wolfram, S. (2017, November 14). What Is a Computational Essay? Stephan Wolfram Writings. https://writings.stephenwolfram.com/2017/11/what-is-a-computational-essay/