
Lebensmitteldaten als Datenkarten
Hier geht es zur Bestellung der Datenkarten. Hier geht es zur Unterrichtsreihe und hier gibt es eine Druckvorlage
Wir stellen hier Unterrichtmaterial vor, das 55 Datenkarten umfasst, die jeweils die typischen sieben Nährwertangaben eines Lebensmittels enthalten, wie z. B. in Abb. 1 für einen Apfel dargestellt. Die Darstellung der Lebensmitteldaten auf Datenkarten wie in Abb. 1 und das Arbeiten mit Daten knüpfen beispielsweise an das Thema Stochastik im Lehrplan NRW für die Erprobungsstufe (Klasse 5 und 6) an. Allerdings werden von Anfang an „multivariate“ Daten, Daten mit mehreren Merkmalen betrachtet, was in fachdidaktischen Vorschlägen schon länger als Bestandteil von Statistical Literacy gefordert wird. Ähnliche Bezüge finden sich auch in anderen Lehrplänen.
Mit den Datenkarten zu Lebensmittelobjekten wird im Unterricht folgende Leitfrage verfolgt:
- Wie kann man mit Hilfe der Datenkarten ein Empfehlungssystem konstruieren, das ein Lebensmittel basierend auf seinen Nährwertangaben möglichst fehlerfrei als eher empfehlenswert oder eher nicht empfehlenswert klassifiziert?

Ein solches Empfehlungssystem bezeichnet man als Klassifikator, da einzelne Objekte (hier Lebensmittel) basierend auf ihren Merkmalen (Nährwertangaben) einer Klasse („eher empfehlenswert“ oder „eher nicht empfehlenswert“) zugeordnet werden, d. h. sie werden klassifiziert. Man bezeichnet das binäre Merkmal ‚Empfehlung‘ als Zielmerkmal und die numerischen Nährwertmerkmale als Prädiktormerkmale.
Ein solcher Klassifikator wird auf der Basis einer Menge von Objekten entwickelt, für die sowohl die Ausprägungen der Prädiktormerkmale als auch des Zielmerkmals bekannt sind. Das sind die sogenannten Trainingsdaten. Ziel ist es aber immer, dass die Empfehlung auch für neue Objekte funktioniert. Zunächst wird das System mit Testdaten getestet, die nicht am Trainingsprozess beteiligt waren, für die aber die Ausprägungen des Zielmerkmals bekannt sind. Man kann damit abschätzen, mit welcher Wahrscheinlichkeit das System neue Objekte mit unbekannter Ausprägung korrekt klassifiziert.
Das Datenbeispiel umfasst 40 blaue Karten zum Erstellen des Empfehlungssystems und 15 gelbe Karten zum Testen. Es werden rote und grüne Büroklammern genutzt, mit denen im Unterricht die konsentierte Ausprägung des Zielmerkmals (auch Label genannt) dargestellt wird. Zum Herstellen eines einheitlich gelabelten Trainingsdatensatzes kann im Unterricht die Ernährungspyramide der Deutschen Gesellschaft für Ernährung (DGE, https://www.dge.de/gesunde-ernaehrung/dge-ernaehrungsempfehlungen/dreidimensionale-dge-lebensmittelpyramide/) genutzt werden.
Ein Entscheidungsbaum als Klassifikator
Im Folgenden wird für Lehrkräfte eingeführt, was ein Entscheidungsbaum ist und wie man einen solchen datenbasiert mit Datenkarten erstellen kann. Auf die unterrichtliche Umsetzung wird erst später eingegangen. Ein Entscheidungsbaum ist ein hierarchisches Regelsystem, das als Klassifikator genutzt werden kann. Ein Beispiel für einen Entscheidungsbaum zum zuvor beschrieben Kontext ist in Abb. 2 dargestellt. Man kann mit diesem Regelsystem z. B. den Apfel aus Abb. 1 klassifizieren, indem man den Entscheidungsbaum von oben nach unten durchläuft und abhängig von den Werten für die Merkmale Fett und Energie die passenden Abzweigungen wählt. Der erste Regelknoten fragt das Merkmal Fett ab. Da der Apfel weniger als 8 g Fett pro 100 g enthält, nimmt man den linken Ast und landet direkt in einem Endknoten (auch Blattknoten) des Entscheidungsbaums. Ein Endknoten enthält als Aufschrift immer eine Ausprägung des Zielmerkmals, die dem zu klassifizierenden Objekt zugeordnet wird. Der Apfel wird dementsprechend als „eher empfehlenswert“ klassifiziert. Bei einem Lebensmittel mit einem Fettwert größer als 8 g müsste man den rechten Ast nehmen und in zweiter Stufe noch den Energiewert betrachten, um in einen Endknoten zu gelangen.
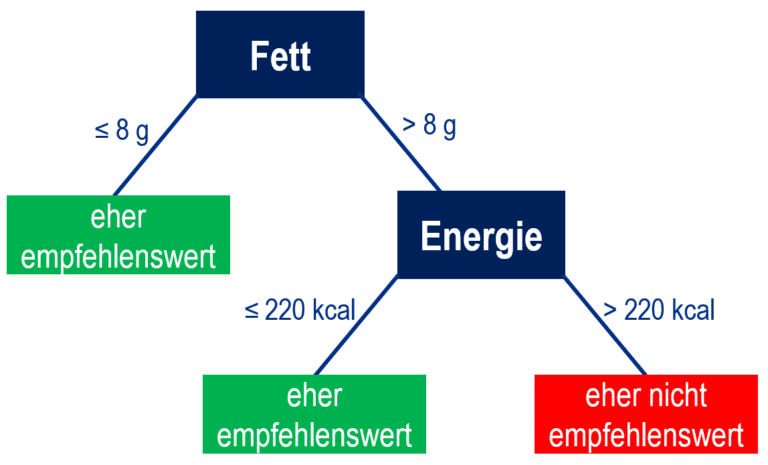
Dieser Entscheidungsbaum ist hier lediglich ein Beispiel ohne den Anspruch, Lebensmittel tatsächlich sinnvoll zu klassifizieren. Prinzipiell kann ein solcher Entscheidungsbaum beliebig viele Stufen und Prädiktormerkmale enthalten. Ziel der Unterrichtsreihe ist, dass Lernende solch einen Entscheidungsbaum datenbasiert selbst erstellen und verstehen, wie Computer so eingerichtet werden können, dass aus den Daten automatisiert Entscheidungsbäume erstellt werden (Maschinelles Lernen als Teil der KI).
Einen Entscheidungsbaum datenbasiert erstellen
Eine Voraussetzung für das datenbasierte Erstellen von Entscheidungsbäumen ist, dass ein Datensatz vorliegt, der aus einer Menge von Beispielobjekten besteht, für die die Ausprägungen des Zielmerkmals und der Prädiktormerkmale bekannt sind. Wir betrachten im Folgenden (Abb. 3 und Abb. 4) beispielhaft elf Lebensmittel als Beispielobjekte, deren Nährwertangaben jeweils auf der Karte angegeben sind. Das sind die Ausprägungen der Prädiktormerkmale Fett, Energie etc. Ferner wird durch eine grüne (bzw. rote) Klammer (als Ausprägung des Zielmerkmals) symbolisiert, ob das Lebensmittel als eher empfehlenswert (bzw. eher nicht empfehlenswert) eingestuft ist. Mit so einer Datengrundlage kann ein Entscheidungsbaum nach und nach aufgebaut werden mit dem Ziel, die Trainingsdaten möglichst fehlerarm zu klassifizieren.
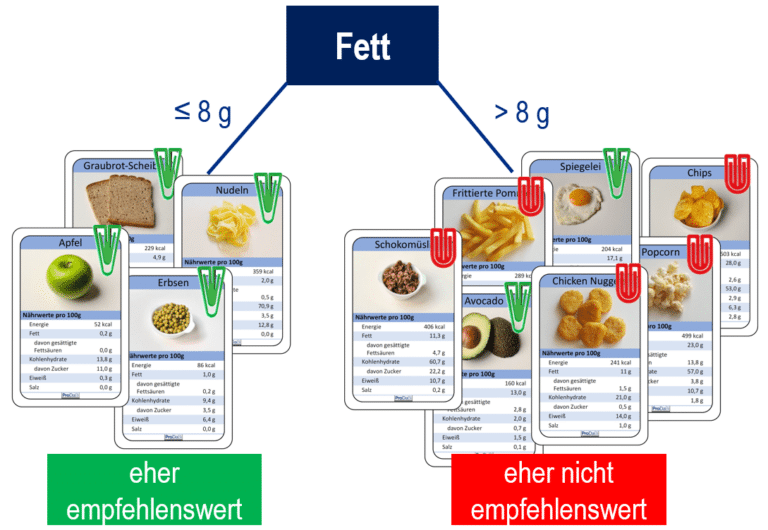
Als Basis für den Erstellungsprozess des Entscheidungsbaums dient der sogenannten Datensplit, d. h. durch ein Prädiktormerkmal und einen Schwellenwert werden zwei Teildatensätze erzeugt (Komponente 1). In Abb. 3 sieht man einen Datensplit mit dem Merkmal Fett und dem Schwellenwert 8 g, d. h. auf der rechten Seite befinden sich alle Lebensmittel mit mehr als 8 g Fett und links mit bis zu 8 g Fett. In beiden Teildatensätzen wird dann eine Mehrheitsentscheidung hinsichtlich des Zielmerkmals gefällt (Komponente 2). Auf der linken Seite in unserem Beispiel sind ausschließlich eher empfehlenswerte Lebensmittel und auf der rechten Seite ist die Mehrheit der Lebensmittel eher nicht empfehlenswert. Die resultierende Entscheidungsregel (wenn ≤ 8 g Fett, dann eher empfehlenswert; wenn > 8 g Fett, dann eher nicht empfehlenswert) kann evaluiert werden (Komponente 3), indem die Anzahl der dadurch im Datensatz falsch klassifizierten Lebensmittel (Fehlklassifikationen) bestimmt wird. In unserem Beispiel sind es zwei Lebensmittel, die falsch klassifiziert werden, nämlich Avocado und Spiegelei auf der rechten Seite. Die Datensplits werden beim Aufbau eines Entscheidungsbaumes so gewählt, dass diese Mehrheitsentscheidungen möglichst wenige Fehlklassifikationen erzeugen. Abschließend kann man den resultierenden einstufigen Entscheidungsbaum repräsentieren (Komponente 4). Dies kann rein verbal geschehen oder durch ein typisches Baumdiagramm. In der Repräsentation des Entscheidungsbaums kommen die Datenkarten nicht mehr vor, aber es sollte statt der Karten (vgl. Abb. 3) die Verteilung des Zielmerkmals in beiden Teildatensätzen (4 zu 0; 2 zu 5) notiert werden, damit die Anzahl der Fehklassifikationen nachvollziehbar ist.
Nun kann man den bisher einstufigen Entscheidungsbaum, der ja zwei Lebensmittel falsch klassifiziert, weiter verbessern, indem man eine weitere Stufe hinzufügt. Die Datenkarten im linken Ast können beiseitegelegt werden, da dort schon alles korrekt klassifiziert wird. Mit den Karten im rechten Ast verfährt man genau wie für die erste Stufe beschrieben. Wenn man das Prädiktormerkmal Energie und den Schwellenwert 220 kcal für einen weiteren Datensplit nutzt, erhält man den Entscheidungsbaum aus Abb. 2, der für dieses Datenbeispiel alle Lebensmittel korrekt klassifiziert.
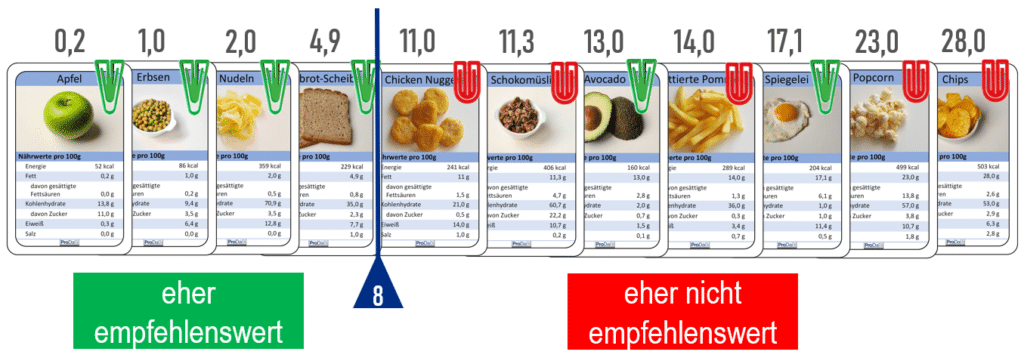
Ein zentraler Aspekt, der bisher noch nicht erklärt wurde, ist wie ein Merkmal und ein Schwellenwert für einen ersten Datensplit und dann für die weiteren „günstig“, also derart, dass möglichst wenig Fehlklassifikationen auftreten, ausgewählt werden. Mit den Datenkarten kann dies durch Sortieren und systematisches Probieren umgesetzt werden.
Ausgehend von den sortierten Datenkarten können verschiedene mögliche Datensplits und die resultierende Anzahl von Fehlklassifikationen miteinander verglichen werden. Für ein gegebenes Datenbeispiel betrachten wir denjenigen Datensplit als optimal, der die geringste Anzahl falsch klassifizierter Objekte liefert. In diesem Beispiel ist der optimale Datensplit der in Abb. 4 visualisierte zwischen der Graubrot-Scheibe und den Chicken Nuggets. Dies kann man überprüfen, indem man systematisch alle Datensplits untersucht. Dafür verschiebt man den trennenden senkrechten Strich einmal in alle Zwischenräume zwischen zwei Karten und wendet jeweils die zuvor erläuterten Komponenten 1-3 an, um die Anzahl falsch klassifizierter Objekte zu ermitteln. Ein Datensplit zwischen Avocado und Pommes liefert z. B. drei falsch klassifizierte Objekte und ist somit schlechter zu bewerten.
Wenn ein optimaler Datensplit ausgewählt ist (in unserem Beispiel mit zwei falsch klassifizierten Objekten), kann ein Schwellenwert im Intervall zwischen den Fettwerten der beiden anliegenden Karten gewählt werden. In Abb. 4 wurde im Intervall zwischen den Werten 4,9 und 11,0 der Wert 8 als Schwellenwert gewählt. Für alle anderen Prädiktormerkmale kann dann auch ein optimaler Datensplit bestimmt werden, um anschließend das Prädiktormerkmal auszuwählen, das eine möglichst geringe Anzahl falsch klassifizierter Lebensmittel liefert. Man geht also mit einer sogenannten „Greedy-Strategie“ vor, d. h. man sucht den besten einstufigen Entscheidungsbaum und betrachtet dann erst die zweiten Stufen und entscheidet, ob dort weitere Datensplits nötig sind. Dort wählt man wieder das beste Merkmal mit dem optimalen Datensplit in der betrachteten Teilmenge der Daten. Es ist diese systematische Methode, die im Wesentlichen in den professionellen Entscheidungsbaum-algorithmen implementiert ist. Dazu gehören dann noch geeignete Abbruchkriterien. In der Unterrichtspraxis ist das Einbeziehen aller Datensplits für Lernende sehr mühsam, sodass (zunächst) etwas vereinfachte Strategien, die bei der Beschreibung des Unterrichts im nächsten Abschnitt erläutert werden, verwendet werden können. Diese Strategien folgen dem gleichen Ansatz und können deshalb die Grundlage dafür liefern, zu verstehen, wie eine Maschine automatisiert, vollständig und systematisch vorgeht.