
Steckbrief des Unterrichtsmoduls
Kernidee:
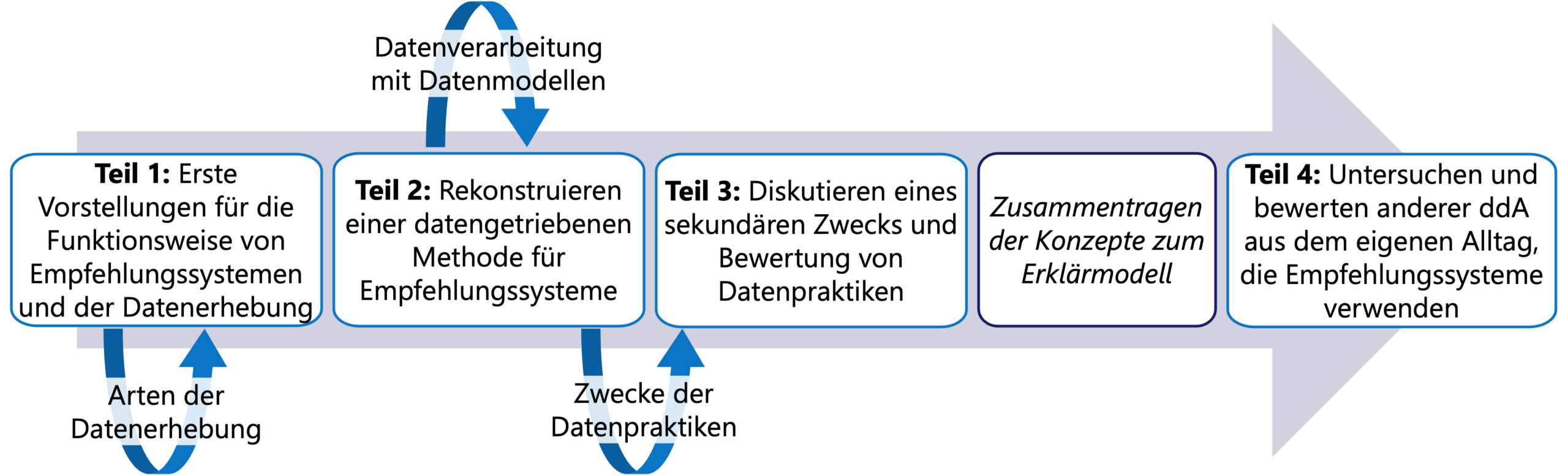
Das Unterrichtsvorhaben setzt sich aus vier Teilen zusammen und thematisiert als Beispielanwendung die Erhebung und Verarbeitung von Daten exemplarisch bei der Nutzung des Streamingplattformen, fokussiert auf den Einsatz von Empfehlungssystemen, und weiterführend in anderen Alltagskontexten der Lernenden.
Im ersten Teil wird in den Kontext der Streamingplattform eingeführt, bei dem Empfehlungssysteme verwendet werden, um personalisierte Filmempfehlungen anzuzeigen. Dabei wird erarbeitet, welche persönlichen Daten bei der Nutzung einer exemplarischen Streamingplattform erhoben werden, um mit diesen personalisierte Filmempfehlungen zu ermitteln. Zum Beispiel sind dafür Nutzungsdaten interessant, wie etwa über die von einem Nutzenden angeschauten Filme. Dafür wechseln die Schüler:innen in die Perspektive eines Anbieters einer Streamingplattform und geben anderen Schüler:innen Filmempfehlungen. Gemeinsam reflektieren sie anschließend ihr Vorgehen und erarbeiten Ideen für die Erhebung persönlicher Daten als Grundlage für das Generieren persönlicher Filmempfehlungen. Im zweiten Teil wird die Funktionsweise eines Filmempfehlungssystemes rekonstruiert, wofür die Schüler:innen in einer vorbereiteten Lernumgebung mit einem gegebenen Filmempfehlungsdienst interagieren und schrittweise die Funktionsweise von der Erhebung von Daten bis hin zur automatisierten Ermittlung von Empfehlungen mit einem Verfahren des maschinellen Lernens erarbeiten (in diesem Falle ist es das k-nearest neighbor Verfahren). Im dritten Teil wird exemplarisch eine Zweitverwertung von Nutzungsdaten durch eine Streamingplattform thematisiert, indem sich die Schüler:innen im Rahmen einer Diskussionsrunde mit dem sekundären Zweck einer personalisierten Bezahlschranke basierend auf der Idee des Empfehlungssystemes auseinandersetzen. Dabei wird der Interaktionskontext hinsichtlich der Erhebung und Verarbeitung persönlicher Daten reflektiert und bewertet. In diesem Teil werden verschiedene Aspekte der Wechselwirkung zwischen Nutzendem und der Streamingplattform (mit Fokus auf Empfehlungssysteme) thematisiert, wie etwa Verstärkungen von Abhängigkeiten im Nutzungsverhalten oder Wirkungen im Sinne der Filterblasen. Im vierten Teil werden zuvor gelernte Konzepte zur Rolle von Daten bei datengetriebenen digitalen Artefakten zu einem Erklärmodell zusammengeführt. Dies wenden sie anschließend auf weitere datengetriebene Anwendungen aus ihrem Alltag an, in denen Empfehlungssysteme eingesetzt werden. Danach stellen sich die Schüler:innen ihre Untersuchungsergebnisse vor und evaluieren und bewerten die Datenerhebung und -verarbeitung in den verschiedenen Beispielen. Dabei reflektieren sie zudem ihre eigene Rolle (inbs. im Hinblick auf ihre Entscheidungs- und Handlungsmöglichkeiten) in diesen Kontexten und nehmen eine begründete Position zu Empfehlungssystemen ein.
Zielgruppe:
Informatik in Klasse 8 bis 10 (Gymnasium, Gesamtschule, Realschule) – Anknüpfung an Politik- und Philospophieunterricht möglich
Inhaltsfeld:
„Informatik, Mensch und Gesellschaft“, „Information und Daten“ und „Künstliche Intelligenz und maschinelles Lernen“ (überwachtes Lernen)
Vorkenntnisse:
Dieses Unterrichtsvorhaben setzt keine besonderen Vorkenntnisse der Schüler:innen voraus. Es sollte jedoch eine grundlegende Erfahrung im Umgang mit dem Computer vorhanden sein. Außerdem sind grundlegende Vorstellungen des Datenbegriffs wünschenswert; entsprechende Einführungen könnten jedoch auch in diesem Modul integriert werden. Ein Verständnis von Konzepten der Künstlicher Intelligenz oder Maschinellem Lernen ist nicht nötig (z.B. überwachtes Lernen etc.); im Gegenteil werden in diesem Modul Aspekte des überwachten Lernens bereits aufgegriffen (insb. ein Beispiel eines solchen Lernverfahrens). In dem Unterrichtsvorhaben wird ein Jupyter Notebook verwendet, wofür keine Programmierkenntnisse vorausgesetzt werden.
Zeitlicher Umfang:
6-8 Unterrichtsstunden je 45 Minuten
Überblick zum Verlauf des Unterrichtsmoduls
Ziele
Im Sinne der Förderung von Datenbewusstsein, ist das übergeordnete Ziel, dass Schülerinnen und Schüler ein Erklärmodell für datengetriebene Technologien lernen, womit sie die Rolle von Daten bei der Nutzung unterschiedlicher Anwendungen erkennen, verstehen und reflektieren können. Dadurch soll ein Beitrag zu einer selbstbestimmten und kompetenten Handlungsfähigkeit in alltäglichen Interaktionen mit datengetriebenen Anwendungen geleistet werden. Konkretisiert wird dies in die folgenden Teillernziele, gegliedert nach den drei Teilen des Unterrichtsvorhabens.
Teil 1: Filmempfehlungen und Datenerhebung durch einen Empfehlungssystem
- Die Schüler:innen verstehen die Bedeutung von personalisierten Filmempfehlungen, indem sie selbst anderen Personen Filmempfehlungen geben und diesen Prozess reflektieren.
- Die Schüler:innen können die Begriffe der explizit und implizit erhobenen Daten unterscheiden und Daten aus dem Kontext eines Empfehlungssystems entsprechend zuordnen.
- Die Schüler:innen begründen die Bedeutung explizit und implizit erhobener Daten zum Ermitteln personalisierter Filmempfehlungen beispielhaft für die Erstellung einer Startseite bei einer Streamingplattform (primärer Zweck).
Teil 2: Aufbau und Funktionsweise von Filmempfehlungssystemen
- Die Schüler:innen können wesentliche Schritte zur automatisierten Ermittlung von personalisierten Filmempfehlungen mit Bezug zur Grundidee des kollaborativen Filterns am Beispiel des Verfahrens k-Nearest Neighbors aus dem maschinellen Lernen beschreiben.
- Die Schüler:innen können die Rolle von Datenmodellen über Nutzende für Empfehlungssysteme erklären.
- Die Schüler:innen können die Begriffe der primären und sekundären Zwecke unterscheiden und Beispiele aus dem Kontext der Empfehlungssysteme zuordnen.
Teil 3: Zweitverwertung durch ein Empfehlungssystem
- Die Schüler:innen können die Datenpraktiken bei einer fiktiven Streamingplattform bewerten, wofür sie die Wechselwirkung zwischen Nutzenden und der Streamingplattform diskutieren.
- Die Schüler:innen können eine begründete Position zum Einsatz von Empfehlungssystemen einnehmen.
Teil 4: Weitere Kontexte mit Empfehlungssystemen
- Die Schüler:innen können Beispiele für datengetriebene digitale Artefakte aus ihrem Alltag, in denen Empfehlungssysteme eingesetzt werden, untersuchen, indem sie die Konzepte des Erklärmodells darauf anwenden.
- Die Schüler:innen können aufbauend auf ihren Ergebnissen der Auseinandersetzung mit Beispielen für datengetriebene digitale Artefakte ihre Rolle in diesen Situationen reflektieren, indem sie vor allem ihre Entscheidungs- und Handlungsmöglichkeiten diskutieren und bewerten.
Zentrale Leitfragen
Teil 1: Filmempfehlungen und Datenerhebung durch einen Empfehlungsdienst
- Was gebe ich einer anderen Person personalisierte Filmempfehlungen und welche persönlichen Informationen über diese Person sind dafür hilfreich?
Teil 2: Aufbau und Funktionsweise von Filmempfehlungssystemen
- Wie können anhand explizit und implizit erhobener Daten automatisiert personalisierte Filmempfehlungen ermittelt werden?
- Welche Rolle spielen Datenmodelle über Nutzende für die Funktionsweise eines Empfehlungssystems?
Teil 3: Zweitverwertung durch einen Empfehlungsdienst
- Wozu könnten Datenmodelle über Nutzende neben dem Zweck der Ermittlung personalisierter Filmempfehlungen ansonsten genutzt werden?
- Welche Bedeutung hat die Rolle von Daten im Rahmen der Nutzung von Streamingplattformen hinsichtlich der Wechselwirkung zwischen Nutzenden und Streamingplattformen?
Teil 4: Weitere Kontexte mit Empfehlungssystemen
- In welchen anderen Kontexten werden Empfehlungssysteme eingesetzt und welche Rolle spielen Daten dort?
- Welche Rolle spiele ich in den anderen Beispielsituationen, insbesondere im Hinblick auf meine Entscheidungs- und Handlungsfähigkeit?
Unterrichtsverlauf
Teil 1: Filmempfehlungen und Datenerhebung durch einen Empfehlungsdienst
| Phase | Inhalt | Ziele | Material |
|---|---|---|---|
|
1a |
Einführung in den Kontext und Problematisierung: Didaktischer Kommentar: |
|
Netflix stellt Beispielbilder für die Plattform bereit, die hier abge-rufen werden können: https://about.netflix.com/de/company-assets
|
|
1b |
Empfehlungsspiel: Bedeutung von Empfehlungen und die zugehörige Datenerhebung Didaktischer Kommentar: |
|
AB1 |
Teil 2: Aufbau und Funktionsweise von Filmempfehlungssystemen
| Phase | Inhalt | Ziele | Material |
|---|---|---|---|
|
2a |
Überleitung zum Empfehlungsdienst im Jupyter Notebook: Didaktischer Kommentar: |
|
Jupyter Notebook |
|
2b |
Rekonstruktion der Datenerhebung und des digitalen Doppelgängers bei einem gegebenen Empfehlungsdienst: Didaktischer Kommentar: |
|
Jupyter Notebook |
|
2c |
Rekonstruktion der Datenverarbeitung zur Ermittlung von personalisierten Filmempfehlungen: Didaktischer Kommentar: |
|
Jupyter Notebook Ggf. AB2 als Sprinteraufgabe |
|
2d |
Überleitung zu sekundären Zwecken (Zweitverwertung): Didaktischer Kommentar: |
|
|
Teil 3: Zweitverwertung durch einen Empfehlungsdienst
| Phase | Inhalt | Ziele | Material |
|---|---|---|---|
|
3a |
Einführung in eine Diskussionsrunde bzgl. einer Zweitverwertung: |
|
|
|
3b |
Diskussionsrunde als Rollenspiel zu einer fiktiven Zweitverwertung: Didaktischer Kommentar: |
|
AB3 in 4 Varianten für die jeweiligen Rollen |
Zwischenphase: Zusammentragen der Konzepte zum Erklärmodell
| Phase | Inhalt | Ziele | Material |
|---|---|---|---|
|
|
Im Sinne einer Zusammenfassung und eines Zwischenfazits sollten nun die zuvor gelernten Konzepte des Erklärmodells zusammengetragen werden. Dafür kann etwa die Abbildung zum Erklärmodell dienen, in denen die verschiedenen Konzepte eingetragen sind. (Hinweis: Die Beschreibung des Erklärmodells kann etwa von der Interaktion aus starten, dann mit der Datenerhebung fortführen und einmal die Schleife mit der Datenverarbeitung und den digitalen Doppelgängern durchlaufen.) |
|
Erklärmodell für Datenbewusstsein (etwas vereinfachte Variante) im Zusatzmaterial |
Teil 4: Weitere Kontexte mit Empfehlungssystemen
| Phase | Inhalt | Ziele | Material |
|---|---|---|---|
|
4a |
Sammlung weiterer Beispiele mit Empfehlungssystemen: Didaktischer Kommentar: |
|
|
|
4b |
Anwendung der zuvor gelernten Konzepte auf ausgewählte Beispiele aus dem eigenen Alltag: Didaktischer Kommentar: |
|
AB4, Internetfähiges Endgerät zur Recherche |
|
4c |
Auswertung und Reflexion der analysierten Kontexte: Didaktischer Kommentar: |
|
|
Genutzte Daten
In diesem Unterrichtsvorhaben ziehen wir reale Nutzungsdaten von Nutzer:innen der Plattform MovieLens (movielens.org) heran. Auf der Plattform angemeldete Nutzer:innen können dort u.a. Filme bewerten und Filmempfehlungen bekommen. Es ist also ein Empfehlungsdienst eingebettet. Die Betreibenden haben Bewertungsdaten öffentlich zugänglich gemacht (Referenz zum Projekt; Referenz zu den Daten). Für das Unterrichtsvorhaben haben wir diese Daten aus Performancegründen verkleinert, sodass wir lediglich ca. 50000 Bewertungen von ca. 5000 User:innen zu insgesamt ca. 600 Filmen nutzen. Die Filme, die bewertet werden können, wurden manuell nach einer subjektiven Einschätzung des Bekanntheitsgrades sowie unter Einbezug von IMDB-Hitlisten ausgewählt. Filme, welche unter den möglichen Empfehlungen erscheinen, haben eines Mindestanzahl an Bewertungen erhalten. Die Nutzer:innen in dem Datensatz wurden so ausgewählt, dass sie alle mindestens einen der Filme, die in diesen Unterrichtsvorhaben bewertet werden können, bewertet haben. Zusätzlich haben wir die Filme in den Daten hinsichtlich der Altersfreigaben gemäß FSK gefiltert, um eine für den Schuleinsatz angemessene Auswahl an Filmen zu bekommen. Für das Unterrichtsvorhaben nutzen wir die Daten in Form von Datentabellen (DataFrames). Diese sind in den nachfolgenden Bildern dargestellt. Sie umfassen in der ersten Datentabelle Informationen über die Filme (Titel, Genre, Erscheinungsjahr) und in der zweiten Datentabelle gerade die explizit und implizit erhobenen Bewertungen der Nutzer:innen (Ids, Datum, Uhrzeit, Fertig_Angeschaut, Rating). Sowohl die Nutzer:innen als auch die Filme bekommen eine ID zugewiesen, mit der sie jeweils eindeutig identifiziert werden.
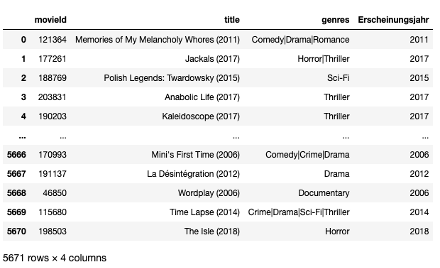
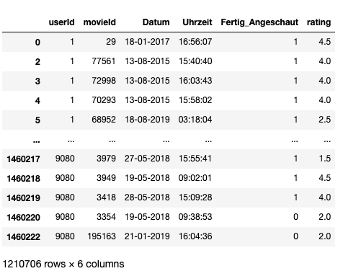
Als optionale Adaption des Jupyter Notebooks wurden in dem Datensatz neben den expliziten Bewertungen zusätzlich implizite Beurteilungen generiert, um die beiden Konzepte zu veranschaulichen. Dabei sind implizite Filmbewertungen im Filmdatensatz die binäre Antwort auf die Frage, ob Nutzer:innen einen Film zu Ende geschaut haben oder nicht. Dieses neue Attribut wurde nachträglich auf Basis der vorhandenen Bewertungen ergänzt. 85% der Bewertungen mit mehr als vier Sternen wurden zufällig auf den Wert 1 (Film zu Ende angeschaut) gesetzt. Bei Bewertungen unter vier Sternen wurden bei 40% zufällig der Wert auf 1 gesetzt. Alle übrigen Bewertungen erhielten den Wert 0 (Film nicht zu Ende angeschaut).
Vorbereitetes Jupyter Notebook
Für dieses Unterrichtsvorhaben haben wir Bibliotheken entwickelt und ein Jupyter Notebook für den Unterricht vorbereitet. In dem Jupyter Notebook (Empfehlungsdienst für Filme.ipynb) werden zunächst die Daten automatisiert eingelesen und ein Empfehlungsdienst beschrieben. Anschließend bekommen die Schüler:innen nach Eingabe von eigenen Bewertungen eigene Filmempfehlungen über einen bereits implementierten Empfehlungsdienst. Dieser basiert auf dem k-Nearest-Neighbor Verfahren (Erklärung siehe unten) und nutzt als Basis seiner Vorschläge die vorgefilterten Bewertungsdaten. In der Standardeinstellung arbeitet der Dienst ausschließlich mit expliziten Bewertungen. Über einen Parameter im Code kann dieser jedoch die Empfehlungen auch basierend auf impliziten Bewertungen berechnen. Im nächsten Schritt wird die Frage thematisiert, welche Daten erhoben wurden. Danach beschäftigt sich das Notebook schrittweise mit der Frage, wie personalisierte Empfehlungen automatisiert berechnet werden können. In dem Jupyter Notebook werden in blauen Boxen die Aufgaben dargestellt sowie in grünen Boxen Einführungs- und Erklärungstexte gegeben.
Wichtiger Hinweis zur Nutzung des Jupyter Notebooks:
Beim ersten Zugriff auf das Verzeichnis mit den Jupyter Notebooks muss man einen Login erstellen, mit dem zu einem späteren Zeitpunkt wieder an die letzte Bearbeitung angeschlossen werden kann. So bleiben die Änderungen auch nach Schließen des Jupyter Notebooks weiterhin bestehen. Das Verzeichnis ist unter folgendem Link zu erreichen: https://go.upb.de/Empfehlungssysteme
Beim ersten Aufrufen muss ein Zugang erstellt werden, wofür Name und Passwort selbst gewählt und eingegeben werden können.
Ansonsten kann das Jupyter Notebook mit den genutzten Daten im folgenden GitHub-Repository bezogen werden: Link zum GitHub Repository
Materialien
Gesammelter Download aller Materialien
Die für das Unterrichtsvorhaben erstellten Jupyter Notebooks und Bibliotheken sowie die verwendeten Daten sind hier zu finden: Link zum GitHub Repository
Was bedeutet Datenbewusstsein?
Im Alltag begegnen uns datengetriebene digitale Artefakte (s. Glossar unten), wie beispielsweise News Feeds in Social Media, Personalisierungen auf Streamingplattformen oder Ergebnislisten von Suchmaschinen. Bei Interaktionen mit datengetriebenen digitalen Artefakten haben Nutzende bestimmte Handlungsziele, die meist auf an den Features des digitalen Artefakts orientiert sind (z.B. Kommunizieren mit Freunden, Finden von interessanten Filmen, Recherchieren von Informationen über etwas). In diesen Interaktionen spielen Daten eine besondere Rolle. Das Konzept Datenbewusstsein zielt gerade darauf ab, Schüler:innen zu befähigen, sich in solchen Interaktionen mit datengetriebenen digitalen Artefakten mit der Rolle der Daten auseinanderzusetzen – also von ihrem eigentlichen Handlungszielen absehen und die Aufmerksamkeit auf die Rolle der Daten richten zu können. Datenbewusstsein bedeutet dabei, dass Schüler:innen in der Lage sind, die Rolle von Daten sowie ihre eigene Rolle in solchen Interaktionen mit datengetriebenen digitalen Artefakten erkennen, verstehen und reflektieren zu können. Damit soll Datenbewusstsein eine selbstbestimmte, mündige und verantwortungsvolle Handlungsfähigkeit in Interaktionen dieser Art fördern.
Für die Rolle von Daten in solchen Interaktionen mit datengetriebenen digitalen Artefakten wurde im Konzept Datenbewusstsein ein Erklärmodell entwickelt (siehe Abbildung 1). Dieses beschreibt fünf Konzepte: (1) die explizite und (2) implizite Datenerhebung, (3) die Konstruktion von Datenmodellen über Nutzende und die für die Datenverarbeitung zugrunde liegenden (4) primären und (5) sekundären Zwecke. Diese Konzepte werden nachfolgend kurz näher beschrieben.
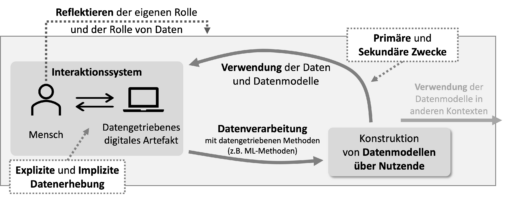
Mit diesem Erklärmodell sollen Schüler:innen eine Orientierung erhalten, aus Sicht dessen sie sich mit datengetriebenen digitalen Artefakten aus ihrem Alltag auseinandersetzen können und die Rolle von Daten sowie ihre eigene Rolle in diesen Interaktionen erkennen, verstehen und reflektieren können. Dadurch sollen Schüler:innen zu einer selbstbestimmten, mündigen und verantwortungsvollen Handlungsfähigkeit in ihren Interaktionen mit datengetriebenen digitalen Artefakten befähigt werden.
Weitere Informationen
Empfehlungssysteme im Allgemeinen (engl.: Recommender Systems)
Ein Empfehlungssystem (auch -dienst genannt) verfolgt das Ziel, die Menge aller vorhandenen Items (z. B. Filme, Musiktitel, Shopping-Produkte, …) auf eine Vorauswahl (Empfehlungen) einzuschränken, um Nutzer:innen bei der Entscheidungsfindung zu unterstützen. Dem Nutzenden werden also nicht alle Items angezeigt, sondern lediglich eine Auswahl, für die sich der Nutzende potenziell interessieren könnte. Die Anbie-tenden des Dienstes zielen damit auf eine Gewinnmaximierung ab, indem „neue und interessante“ Items „entdeckt“ werden. Dadurch werden die Nutzer:innen zu längeren und häufigeren Zugriffen (Steigerung der Nutzungszeit) angeregt, wodurch sie mehr Daten hinterlassen und womöglich der Umsatz durch Käufe oder Werbungen gesteigert werden kann.
Im Wesentlichen gibt es inhaltsbasierte (content-based), kollaborative (collaborative) und hybride Methoden zum Filtern der Items. Beim kollaborativen Filtern werden ähnliche Nutzer:innen identifi-ziert, um dann Empfehlungen basierend auf deren Daten (bspw. Filmbewertungen) zu ermitteln (hier etwa: Mittelwerte der Bewertungen der ähnlichen Nutzer:innen). Beim inhaltsbasierten Filtern wer-den Daten herangezogen, welche inhaltliche Informationen über die Produkte enthalten bzw. zumin-dest operationalisieren (z.B. Tags, Genres, Wortvorkommen in Textbeschreibungen). Das hybride Filtern verbindet verschiedene Methoden des kollaborativen und inhaltsbasierten Filterns – i.d.R. nach-einander.
Erklärung des k-Nearest-Neighbor Verfahrens
Im Unterricht wird das k-Nearest-Neighbor Verfahren genutzt. In der folgenden Abbildung ist ein Minimalbeispiel gegeben, anhand dessen die grundlegende Idee des Suchens von k nächsten Nachbarn erklärt werden kann. Es gibt Bewertungsdaten von fünf Nutzer:innen zu insgesamt drei Filmen. Gesucht sind zum Beispiel zwei Nutzer:innen (k=2), die ähnlich zum markierten User 5 sind. Das sind dann etwa die User 1 und 4, da diese die kleinste Abweichung in ihren Bewertungen der beiden Filme zu User 5 haben. Konkret heißt das, dass die Abstände zwischen der Tabellenzeile von User 5 und denen von User 1 und 4 am kleinsten sind, die Differenz also möglichst klein ist. (Anmerkung: Mathematisch nutzen wir in unserer Umsetzung die euklidische Metrik für die Bestimmung von Abständen.) Um nun für einen dritten Film C zu entscheiden, ob dieser dem User 5 empfohlen werden sollte, werden die Bewertungen der ähnlichen Nutzer:innen betrachtet. Anhand dieser Bewertungen kann etwa ein Mittelwert berechnet werden (in diesem Fall: 4.5), der als Vorhersagewert für den User 5 gilt. Das heißt, wenn User 5 den Film C schauen und bewerten würde, würde er wahr-scheinlich eine Bewertung von 4.5 abgeben. Dem User 5 sollte der Film C also durchaus empfohlen werden. Dieses (hier stark reduzierte) Verfahren ist auf eine große Anzahl von Nutzer:innen und Filmen übertragbar.
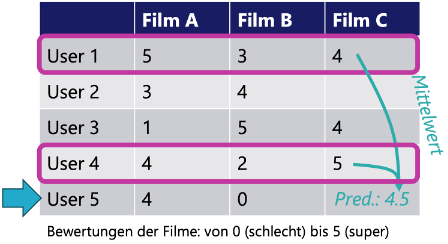
Ähnlich zu diesem reduzierten Beispiel mit fünf Nutzenden und drei Filmen rekonstruieren die Schüler:innen im Unterricht die systematische Idee der kollaborativen Filtermethodik basierend auf Ähnlichkeiten von Nutzenden (d.h. es werden ähnliche Nutzende gesucht und anhand derer Bewertungs-/Nutzungsdaten wird entschieden, ob ein dritter Film einem Nutzenden empfohlen werden sollten.
Empfehlungssysteme im Allgemeinen (engl.: Recommender Systems)
In diesem Unterrichtsvorhaben liegt ein Fokus auf Streamingplattformen, wodurch vor allem Plattformen wie Netflix und Spotify im Mittelpunkt stehen. Trotzdem ist dieser Markt stetig am Wachsen: Amazon Prime Video, Disney+, Apple Music oder Amazon Music sind nur einige der Wettbewerber:innen. Schon seit dem Aufkommen von modernen Streamingplattformen arbeiten diese an folgender Frage: Wie können einem Kunden/einer Kundin möglichst maßgeschneiderte (personalisierte) Produktempfehlungen angeboten werden und wie können somit möglichst viele Kund:innen zum Bezahlen im jeweiligen Preismodell motiviert werden?
Folgende zwei Zitate zu Empfehlungssystemen bei Netflix und Spotify illustrieren dies:
“A problem we face is that our catalog contains many more videos than can be displayed on a single page and each member comes with their own unique set of interests. Thus, a general algorithmic challenge becomes how to best tailor each member’s homepage to make it relevant, cover their interests and intents, and still allow for exploration of our catalog.” – Nextflix TechBlog
“Spotify has created engines to control and manage everything from your personal best home screen to carefully chosen and organized playlists like Discover Weekly, and continues to explore new ways to understand music, and why people listen to one song or genre over another. All this is achieved with a combination of different recommender systems.” – Daniel Roy
Netflix steht mit seinen über 15000 Filmen und Serien und über 200 Millionen zahlenden Abonnenten weltweit (Stand 2023) vor der Herausforderung, dass es seinen Nutzer:innen nur eine begrenzte Anzahl an Film- und Serientiteln vorschlagen und auf der Startseite anzeigen kann. Ein vergleichbares Bild ergibt sich bei Spotify, wo sich zwar ein anderes Produkt wiederfindet, der Aufbau der Plattform-Seite und die Datenbasis jedoch ähnlich sind. Der Einsatz von Empfehlungssystemen in diesen Plattformen wird recht gut daran deutlich, wie die Startseiten erzeugt werden. (Abbildungen zur Erklärung der Sortierung der Inhalte bei Netflix: Blogpost Netflix). Bei diesen Startseiten werden sowohl Reihen als auch Spalten abhängig von dem/der Nutzer:in sortiert. Das Geschäftsmodell von Netflix ist abonnementbasiert. Dabei gibt es jeweils verschiedene Abo-Pläne, welche im Einzelnen jedoch nicht das Angebot erweitern, sondern z. B. die Anzahl der Nutzenden pro Account verändern. Das Ziel ist es also, die Anzahl der zahlenden Kund:innen zu maximieren und Abonnements immer wieder zu verlängern. Dies wird dadurch erreicht, möglichst passende Vorschläge für Filme/Musik zu realisieren. Neben Streamingplattformen mit vollem Zugriff auf das komplette Angebot nach Zahlung einer monatlichen Rate gibt es auch andere Geschäftsmodelle, wie etwa bei Amazon Prime Video. Diese Plattform stellt nach einem Abonnement ebenfalls einen Teil seines Film- und Serienangebots zur Verfügung. Darüber hinaus gibt es jedoch Medien, welche nach wie vor durch die Zahlung eines einmaligen Betrages freigeschalten werden müssen.
Erhebung von Daten bei der Nutzung von Streamingplattformen
Das Nutzungsverhalten der Nutzer:innen ist für Empfehlungssysteme essenziell. Dabei spielen grundsätzlich jegliche Arten von Interaktionen der Nutzer:innen mit dem System eine Rolle. Dies fängt bei einfachen Feedbackmechanismen an, wie etwa der “Gefällt mir”-Button, und geht weiter zum Nutzungsverhalten über angeschaute Filme und angehörte Musik. Dabei spielen im Grunde immer ähnliche Daten eine Rolle. Auf der einen Seite die verschiedenen Produkte, welche auf der Plattform angeboten werden (Filme, Videos, Bücher, …). Auf der anderen Seite stehen die Nutzer:innen und ermöglichen die Erhebung und Generierung von Daten durch die Interaktion mit den jeweiligen digitalen Artefakten (Schreiben von Rezensionen, Ansicht von Produkten, Verbindungen zu anderen Nutzer:innen, …). Durch diese und weitere erhobene Daten werden von Nutzenden digitale Doppelgänger konstruiert. Auf Basis dessen können dann Empfehlungen ermittelt werden. Interessant für Empfehlungssysteme sind insbesondere Bewertungen für Produkte, wie bspw. Filme, die explizit oder implizit vorliegen können. Explizit sind Bewertungen dann, wenn der/die Nutzer:in das Produkt direkt beurteilt, bspw. über ein Gefällt-mir-Button oder eine Sternebewertung. Dadurch gibt der/die Nutzer:in i.d.R. seine Meinung zu dem Produkt bzw. sein Interesse an dem Produkt aktiv zum Ausdruck. Implizite Bewertungen werden nicht von dem/der Nutzer:in direkt angegeben. Das bedeutet, dass bestimmte Daten erhoben, generiert und verarbeitet werden, welche bspw. als Operationalisierung für das Interesse an dem Produkt dienen können. Beispiele für implizite Bewertungen sind: Hat der/die Nutzer:in das Produkt gekauft? Hat er oder sie den Film vollständig geschaut oder früher beendet? Wurde der Film mehrmals geschaut? Wurde sich das Produkt gemerkt (Merklisten)?
Glossar relevanter Begriffe
Datengetriebene digitale Artefakte: Im Konzept Datenbewusstsein wurde der Begriff der datengetriebenen digitalen Artefakte (ddA) eingeführt. Dieser beschreibt eine spezielle Art von digitalen Artefakten. Digitale Artefakte sind ein Sammelbegriff für digitale Werkzeuge, Computersysteme aller Art, ihre Bestandteile, ihre Verbindung untereinander. Sie umfassen sowohl Hardware, Software, Daten und Objekte sowie Algorithmen und Datenstrukturen. Datengetriebene digitale Artefakte sind dann digitale Artefakte, die sich selbst oder ihre Rückmeldung in der Interaktion mit diesem durch die Verarbeitung erhobener Daten verändert. Diese nutzen dann oft zum Beispiel auch Methoden des Maschinellen Lernens.
Explizite und implizite Datenerhebung:Im Konzept Datenbewusstsein wurden die Begrifflichkeiten der explizit und implizit erhobenen Daten eingeführt. Diese stehen in der Regel in der Verbindung zum Nutzenden – oft stellen sie personenbezogene Daten dar. Die explizit erhobenen Daten sind jene, die der Nutzende mit seiner Handlung intendiert zu erstellen, also direkt und aktiv eingibt bzw. erzeugt. Darüber sind sich Nutzende in der Regel bewusst. Dies sind zum Beispiel bei Social Media Plattformen gepostete Texte und Bilder, bei einer Suchmaschine etwa der Suchbegriff. Im Gegensatz dazu, werden implizit erhobene Daten indirekt durch Beobachtung (Tracking) oder Verarbeitung bereits erhobener Daten nebenher zur eigentlichen Handlung des Nutzenden erhoben und generiert. Dieser Datenerhebung sind sich Nutzende oft nicht bewusst. Im Beispiel der Social Media Plattform sind dies etwa Likes und Klicks, bei der Suchmaschine etwa Klicks auf Suchergebnisse. Die implizite Datenerhebung umfasst zudem die Generierung von Daten, wie etwa im Kontext der Empfehlungssysteme die Vorhersagen für Inhalte, mit denen der Nutzende bisher noch nicht interagiert hat.
Primäre und sekundäre Zwecke der Datenverarbeitung: Im Konzept Datenbewusstsein wurden die Begrifflichkeiten der primären und sekundären Zwecke der Verarbeitung und Verwendung erhobener Daten eingeführt. Diese beziehen sich auf die Verarbeitung und Verwendung von Daten über einen Nutzenden, die bei der Nutzung von datengetriebenen digitalen Artefakten erhoben werden. Primäre und sekundäre Zwecke beziehen sich auf die Intention, mit der diese zuvor erhobenen Daten verarbeitet und verwendet werden. Primäre Zwecke umfasst, dass die erhobenen Daten dazu verarbeitet und verwendet werden, um das datengetriebene digitale Artefakt mit den Features anbieten zu können. Diese beziehen sich auf einer Nutzerperspektive auf die Verarbeitung und Verwendung: Die Daten werden verarbeitet und verwendet, um Nutzenden Features anbieten zu können. Im Beispiel der Suchmaschine ist dies etwa das Anzeigen von Suchergebnissen. Auch inbegriffen wäre, wenn die Suchergebnisse personalisiert geordnet werden. Im Sinne des Features für den Nutzenden würde dies bedeuten, dass der Nutzende gerade die Ergebnisse angezeigt bekommt, die für ihn idealerweise relevant sind. Sekundäre Zwecke bedeutet, dass die Daten anderweitig verarbeitet werden. Diese „Zweitverwertung“ der Daten bezieht sich auf einer Anbieter:innenperspektive auf die Verarbeitung und Verwendung der erhobenen Daten: Wozu kann ein:e Anbieter:in eines datengetriebenen digitalen Artefakts die erhobenen Daten noch nutzen? Im Kontext von Streamingplattformen (z.B. Spotify) könnte dies etwa umfassen, dass Nutzungsdaten (z.B. gehörte Musik) zur Analyse der Emotionen der Nutzenden verwendet werden.